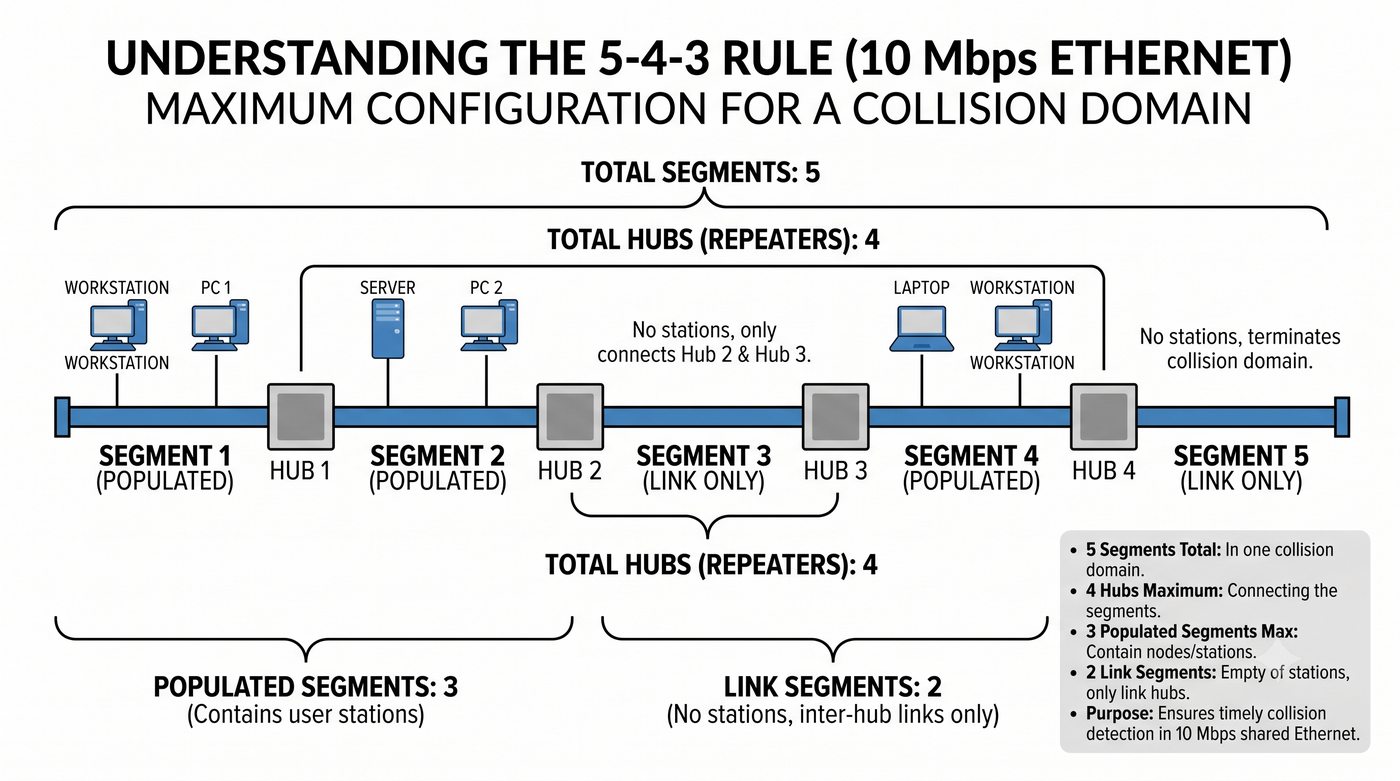
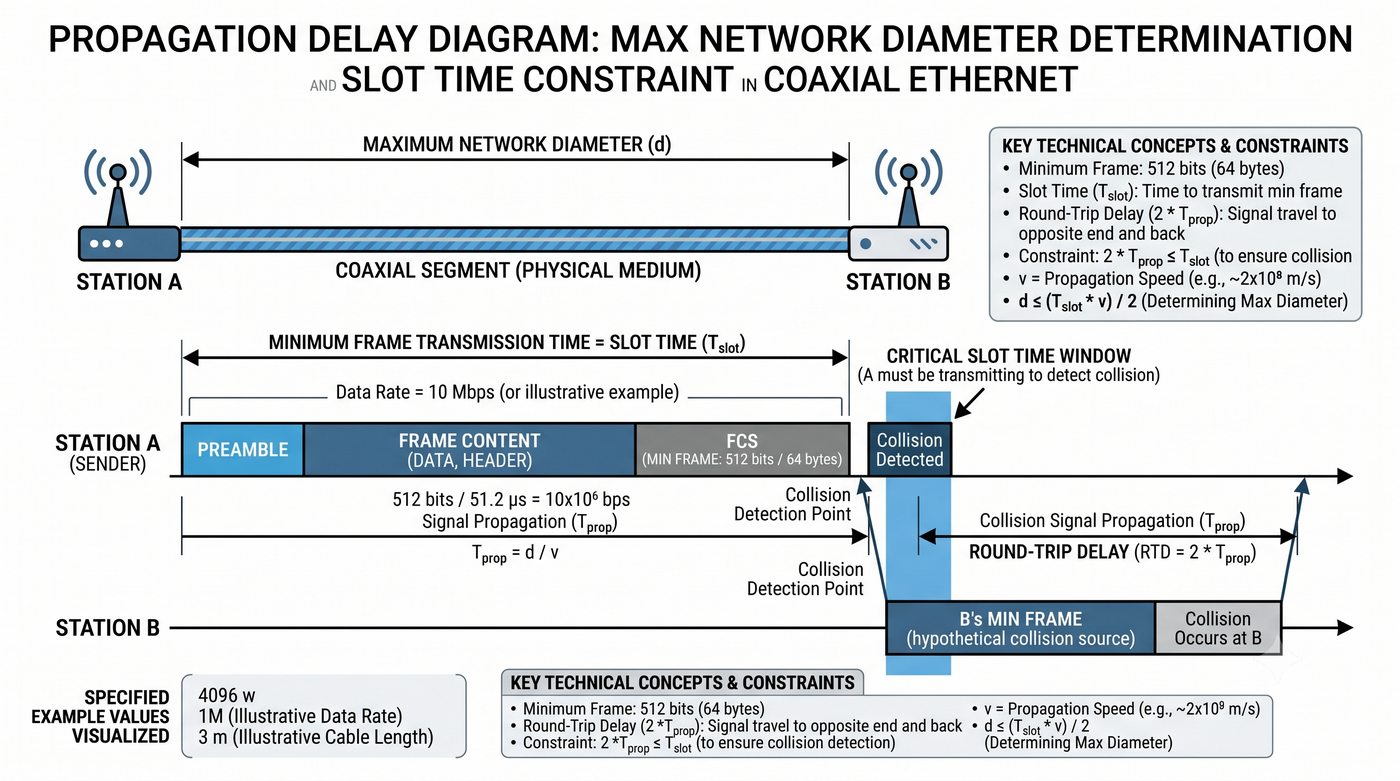
Budowa i konfiguracja urządzeń sieci LAN – koncentratory i przełączniki Ethernet
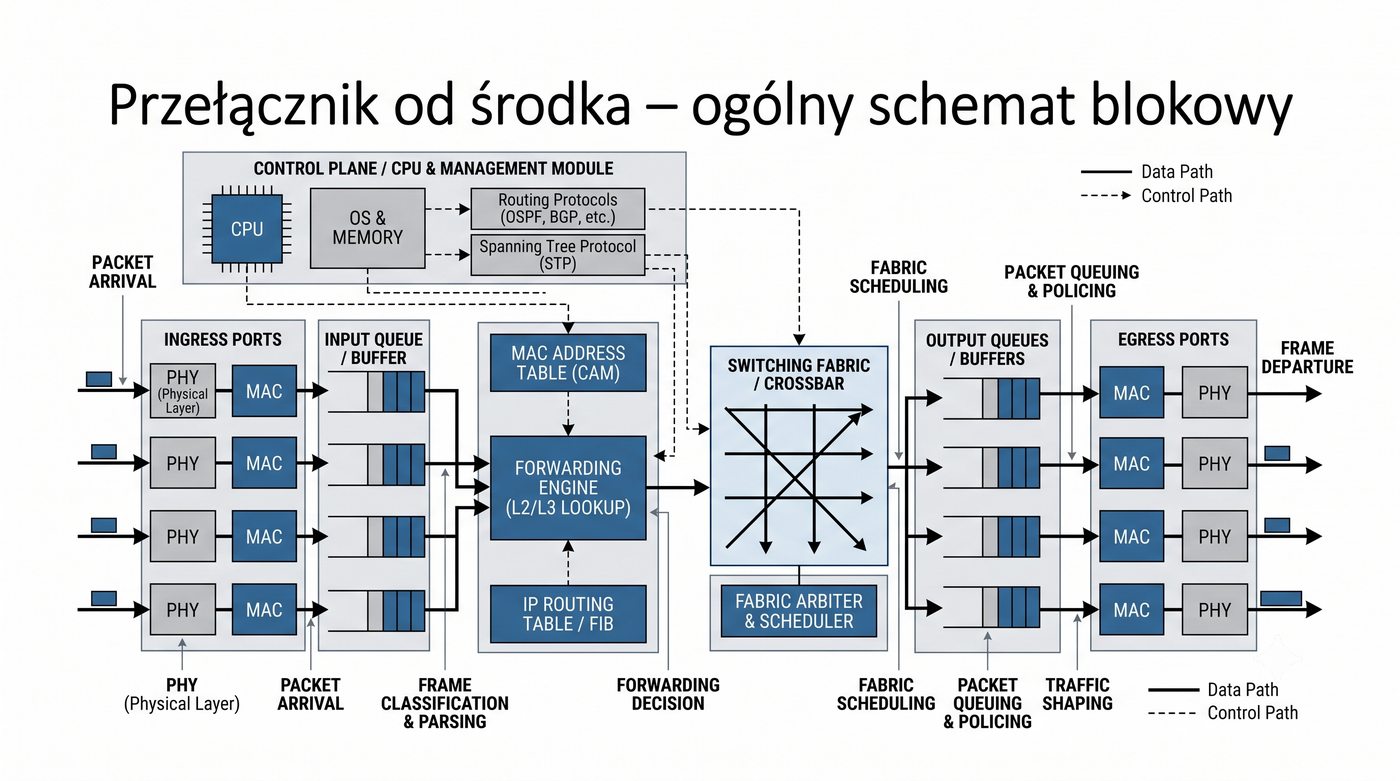
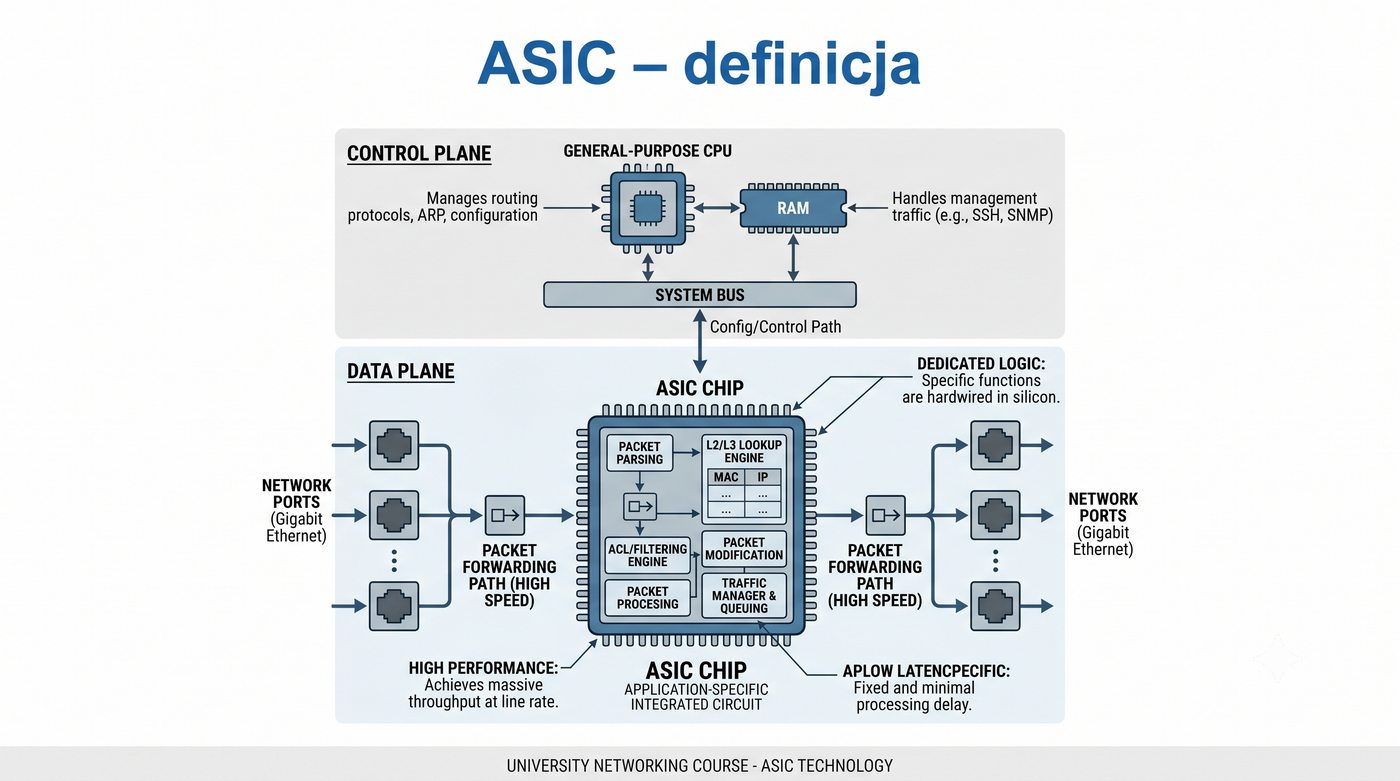
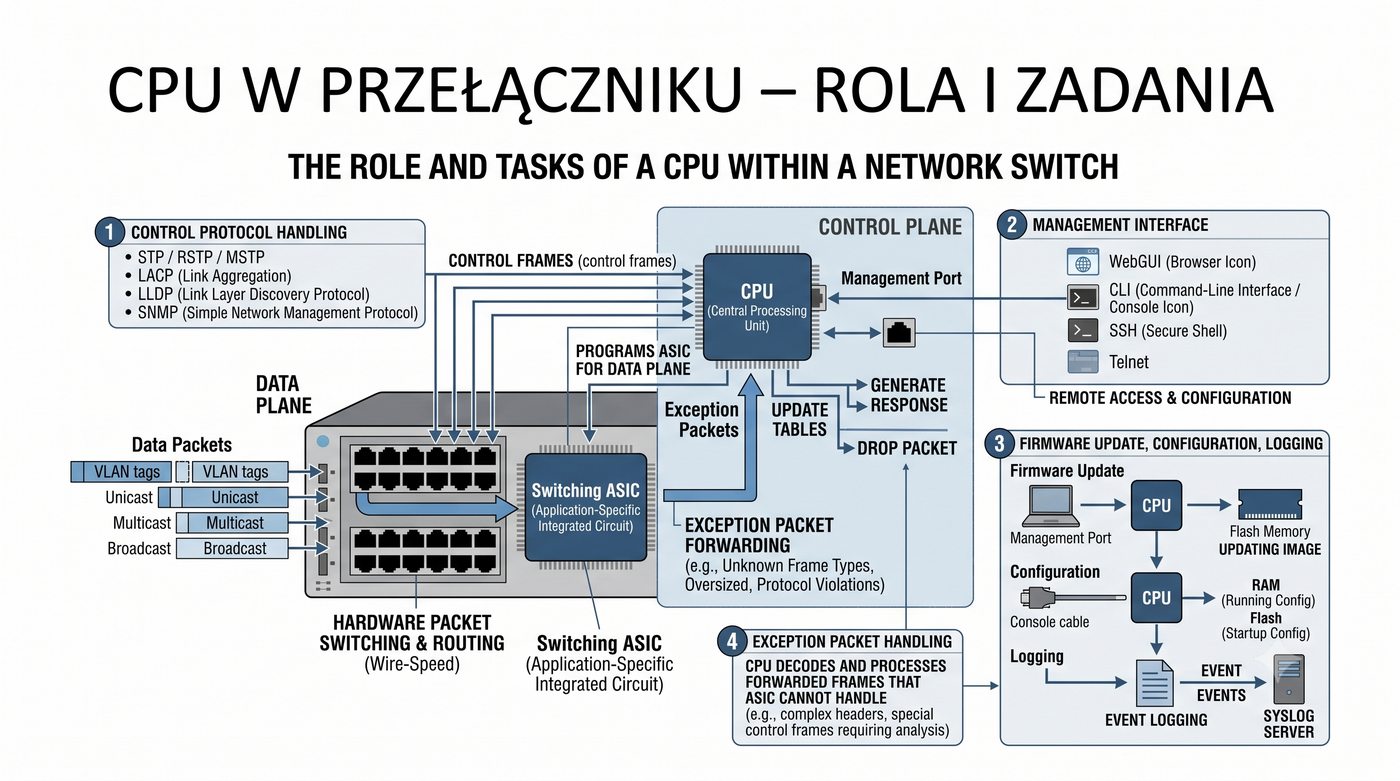
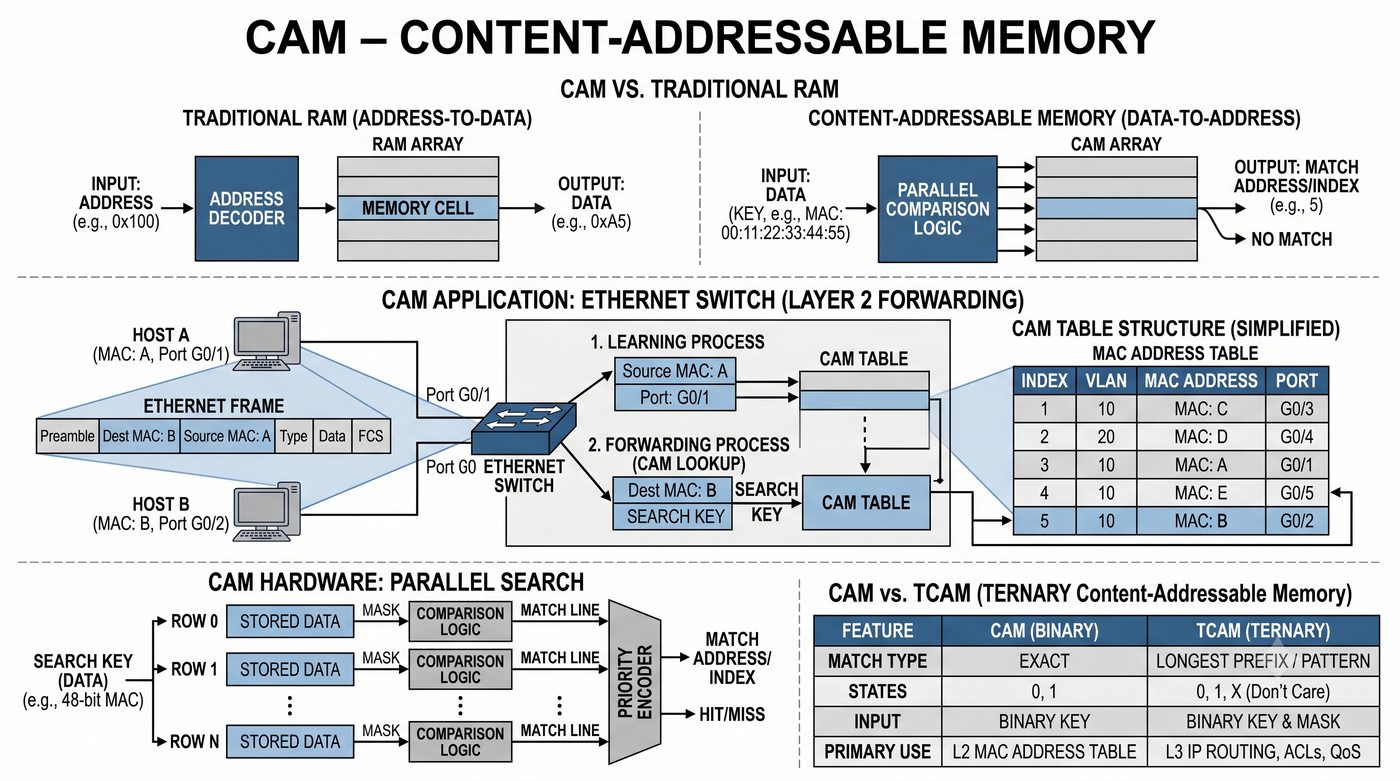
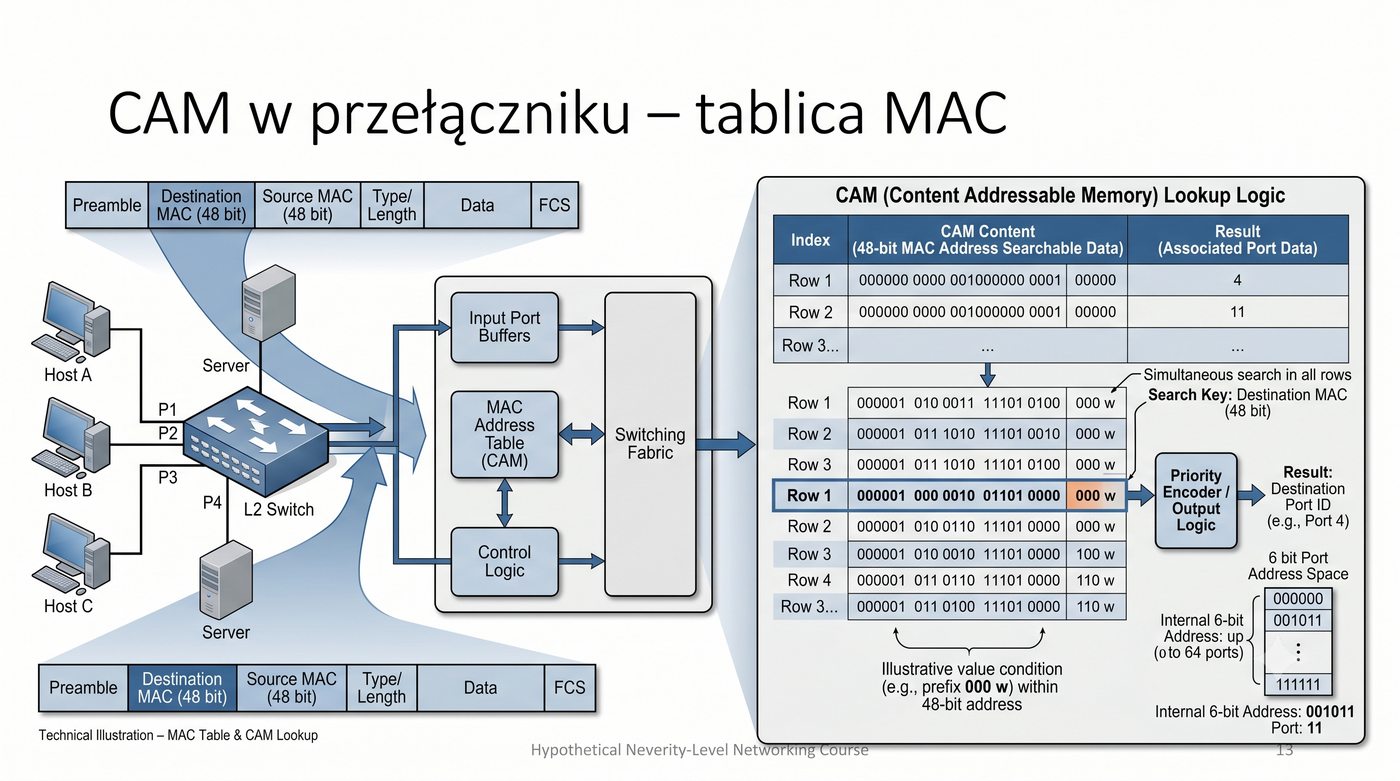
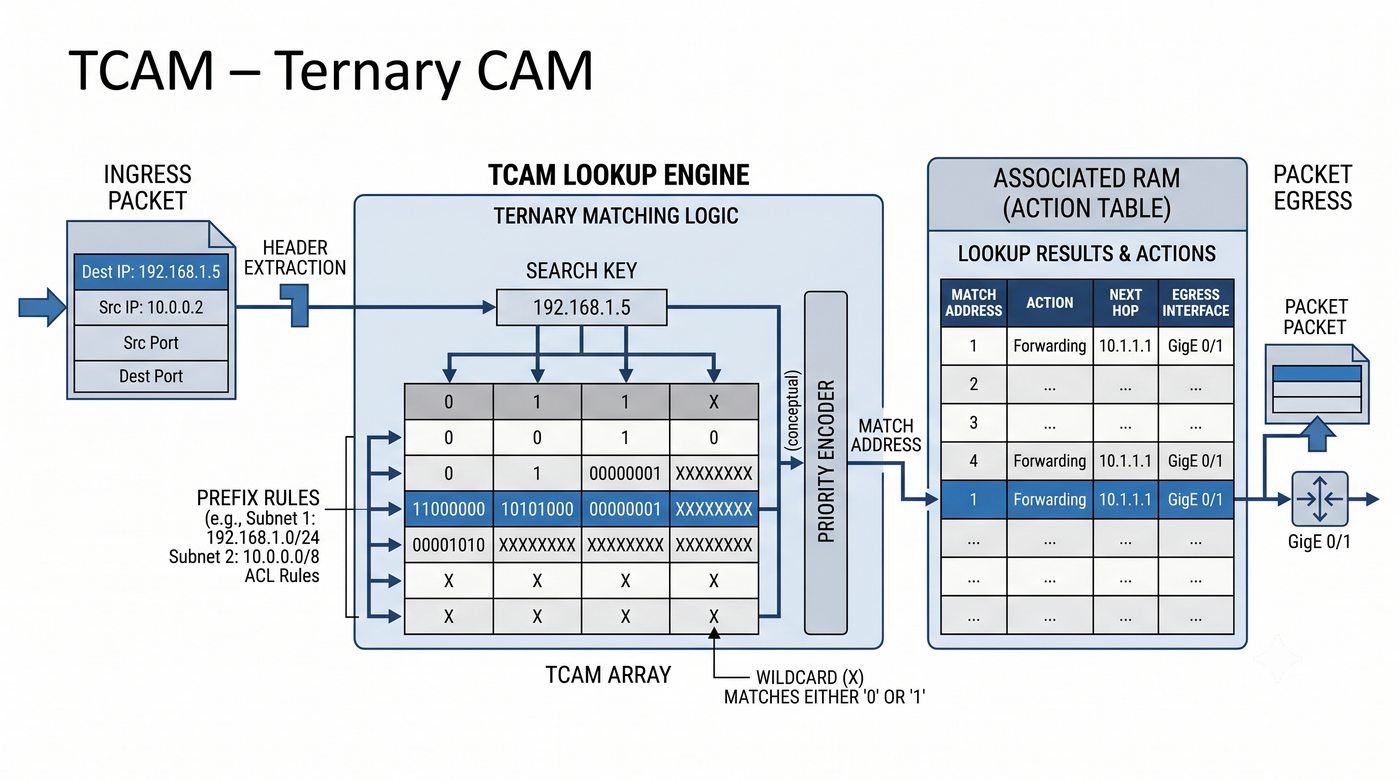
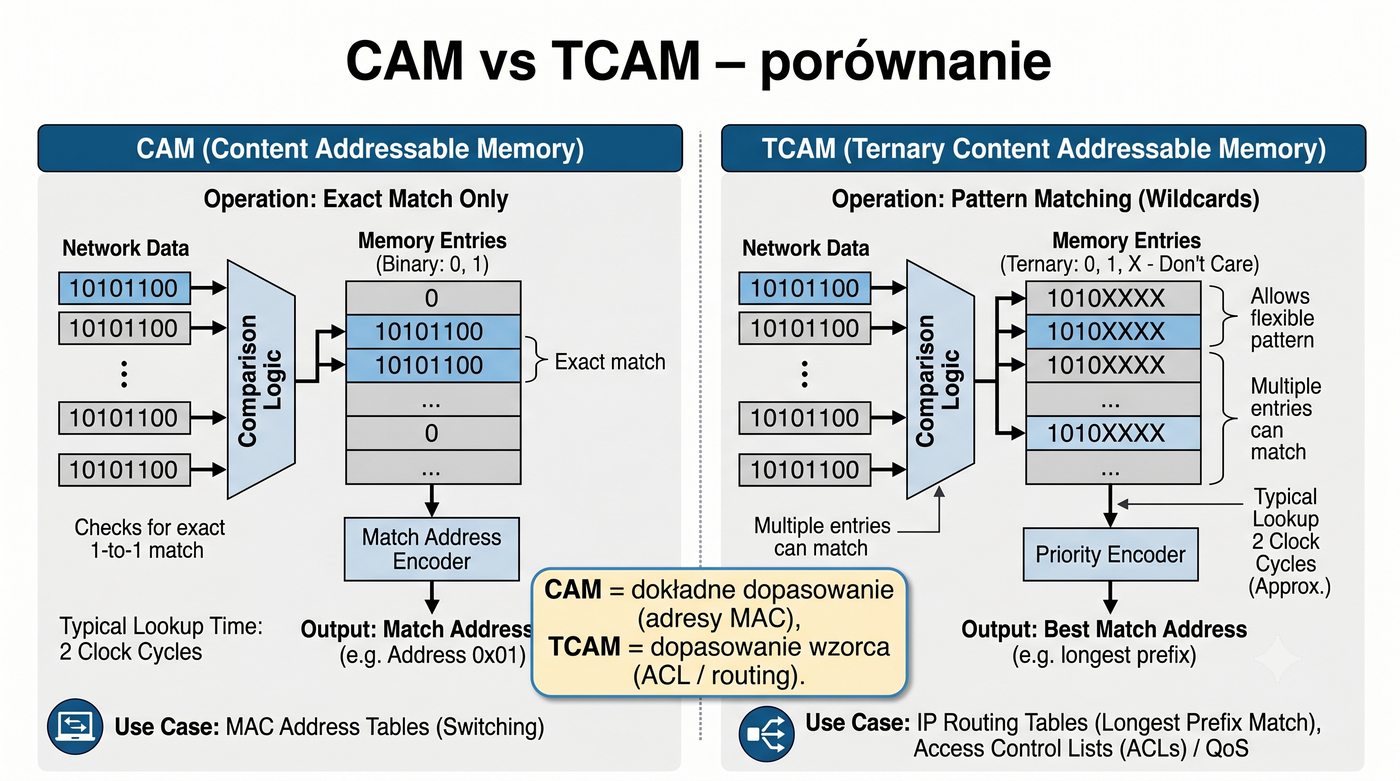
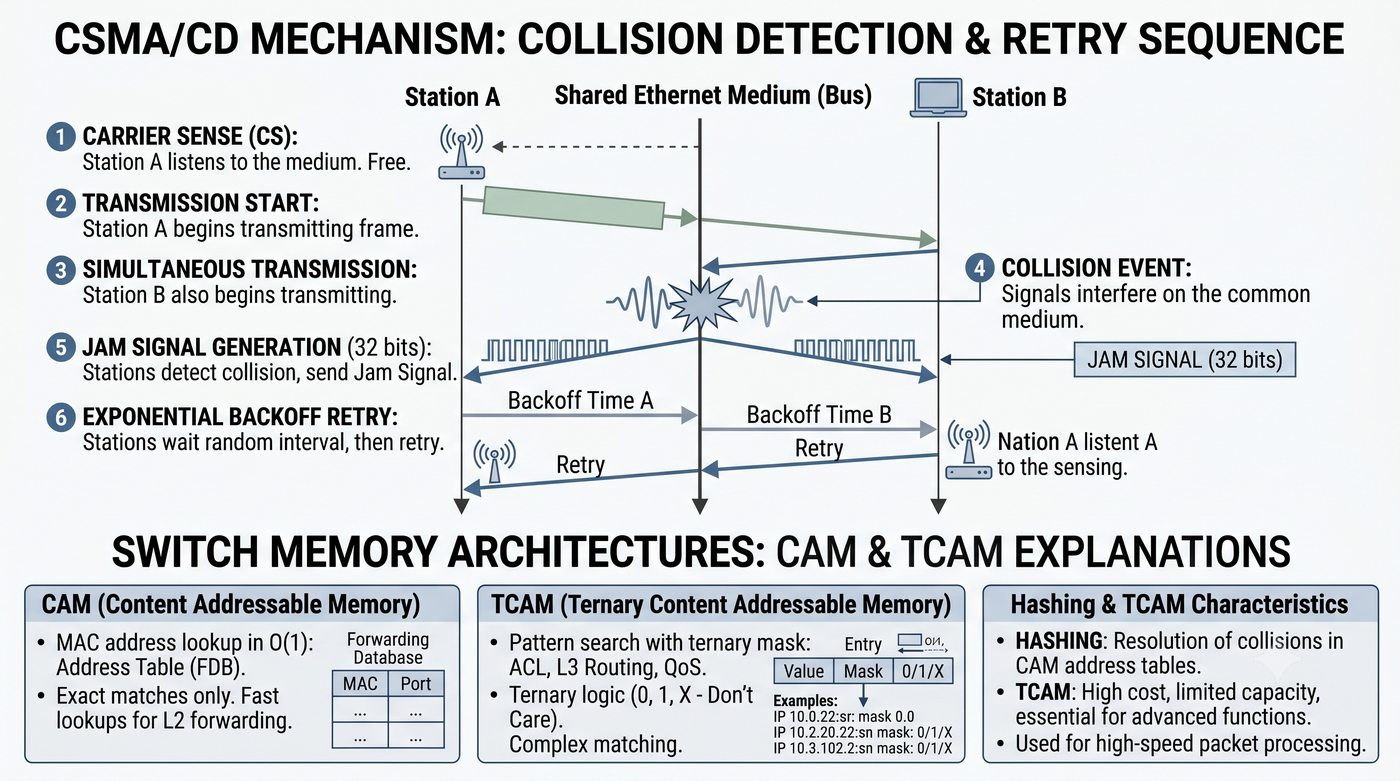
ASIC, CPU, pamięć buforowa, CAM/TCAM – bloki funkcjonalne przełącznika
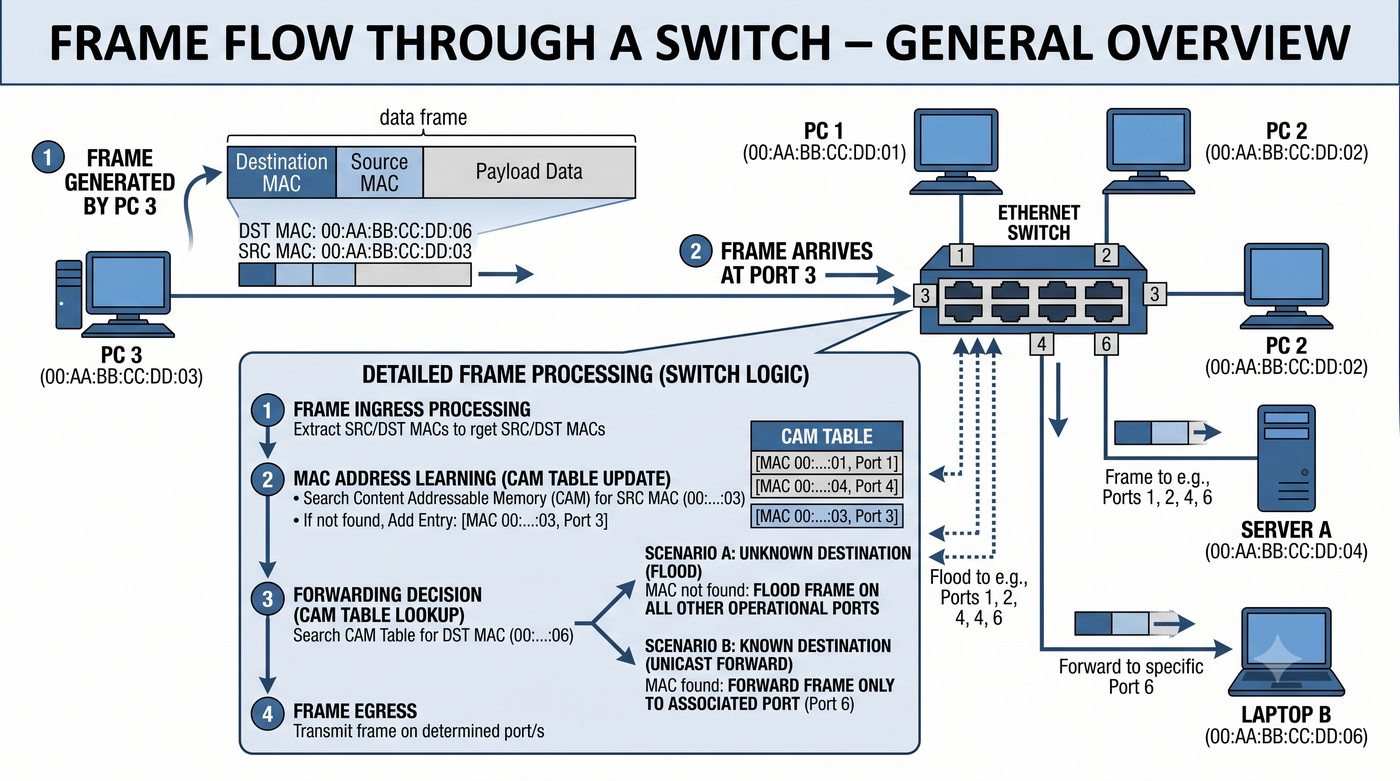
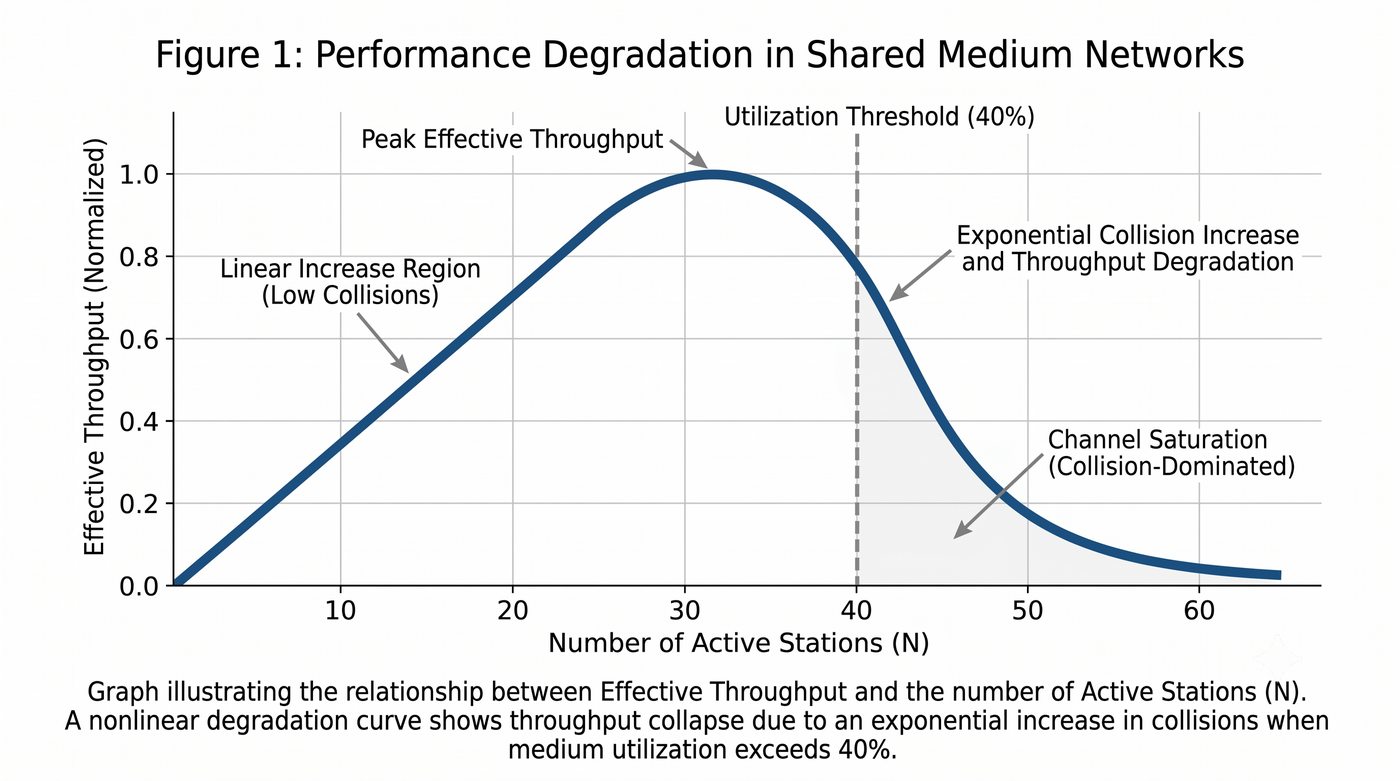
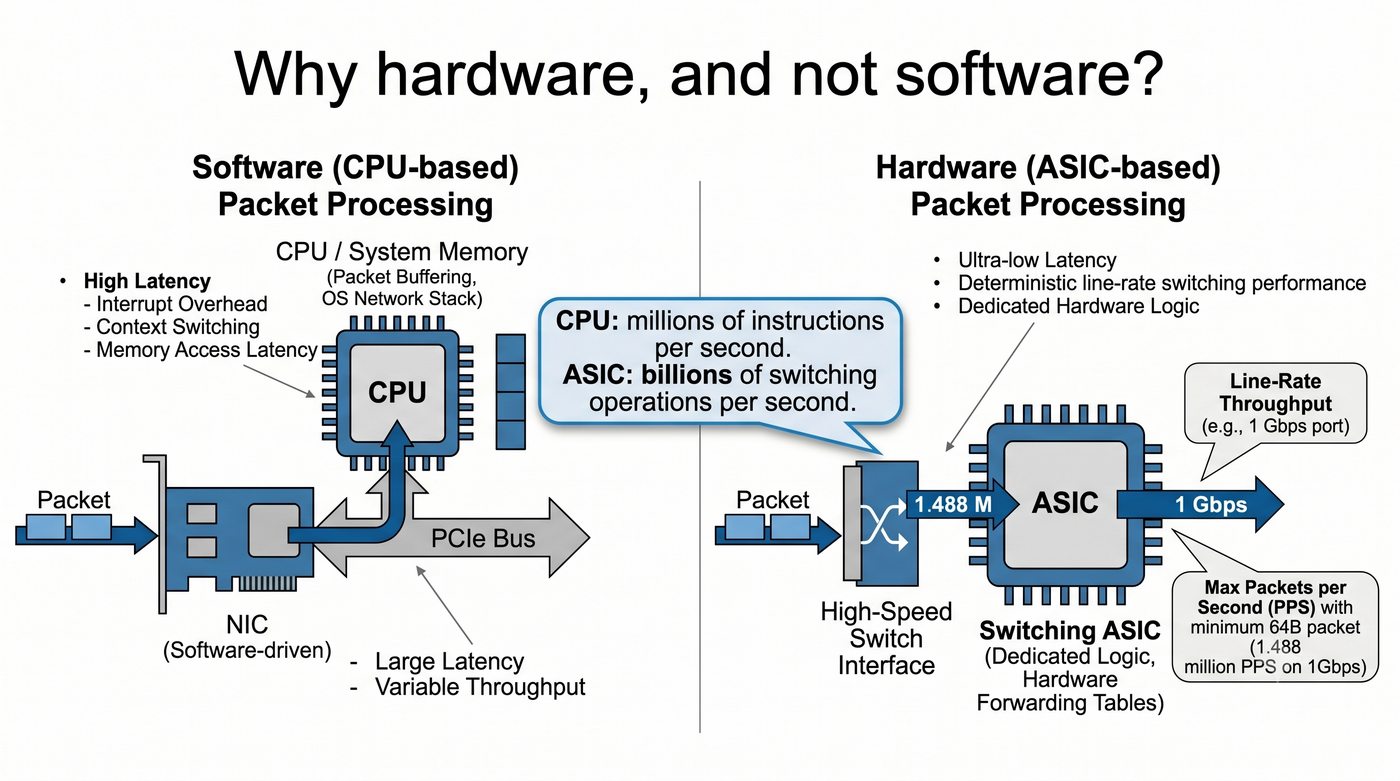
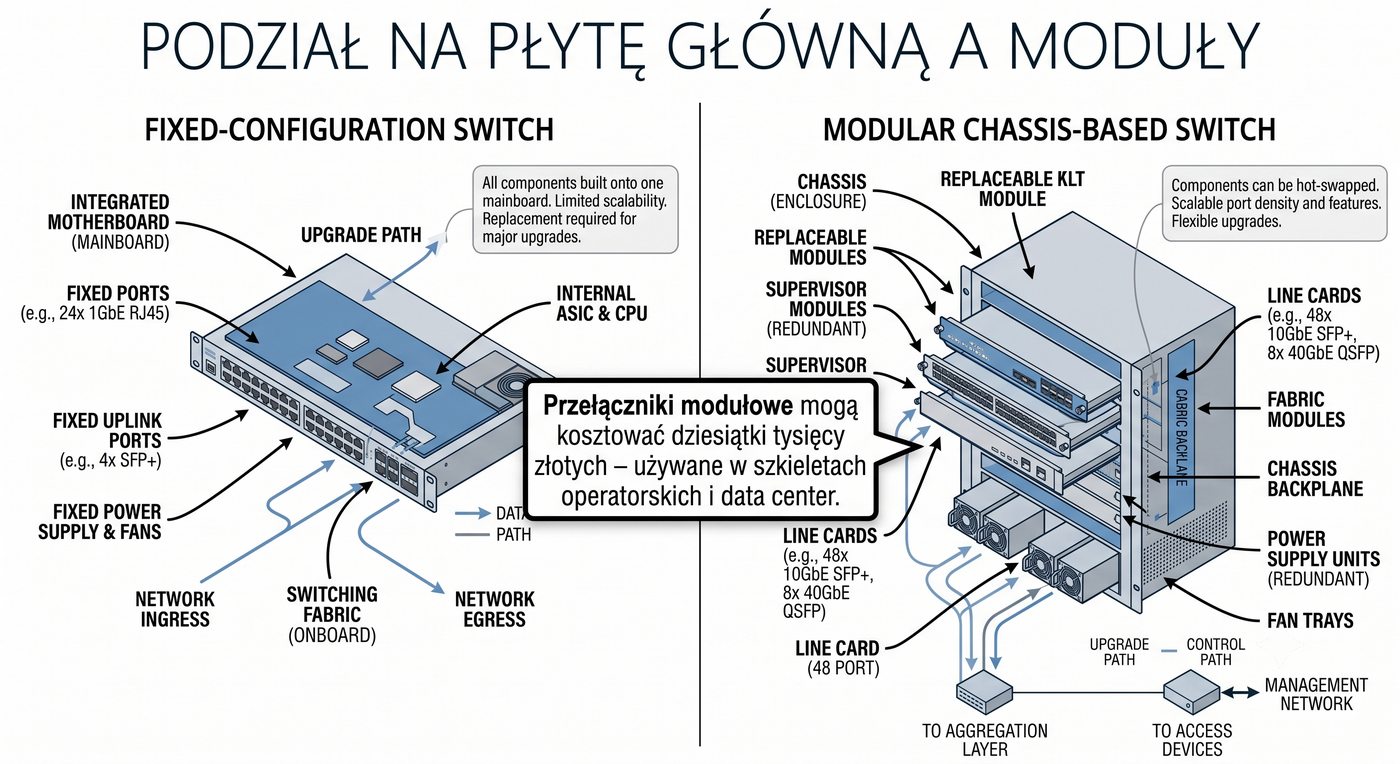
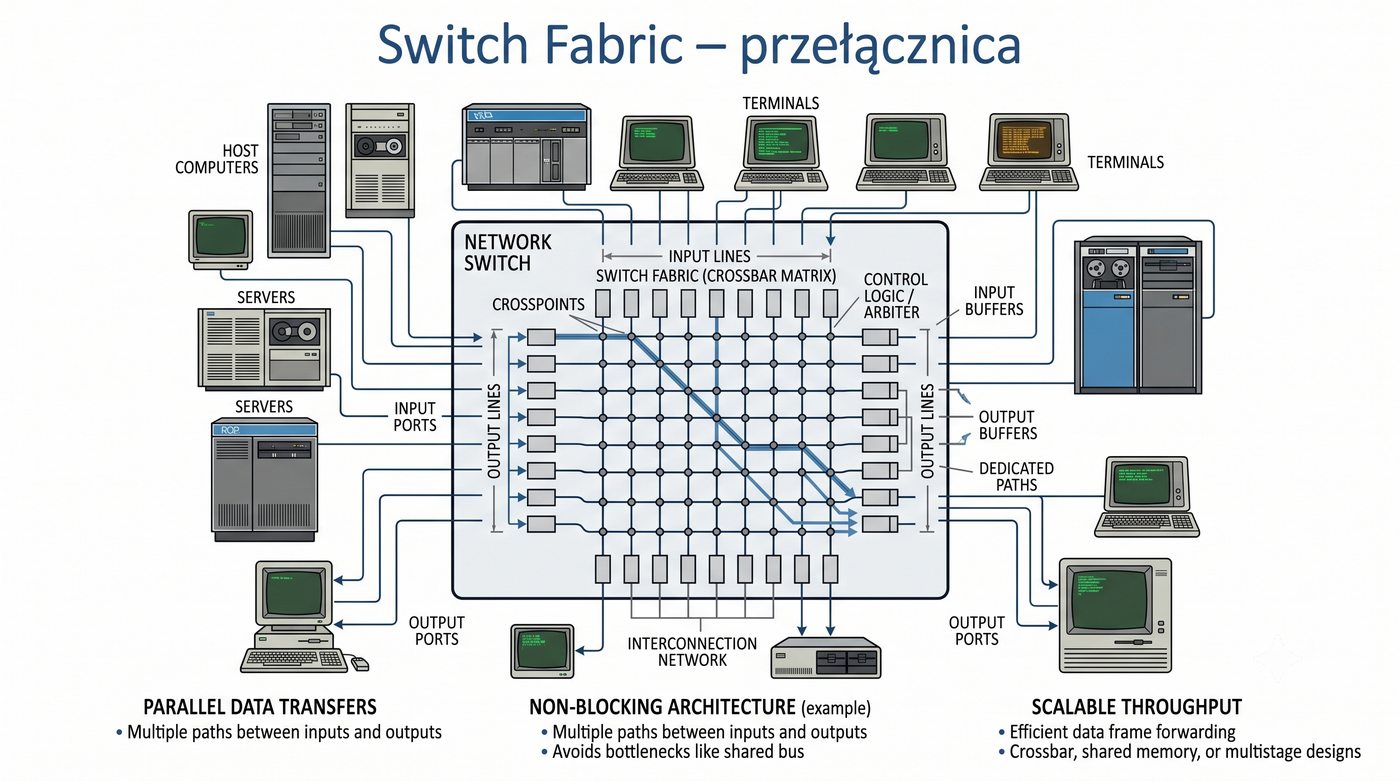
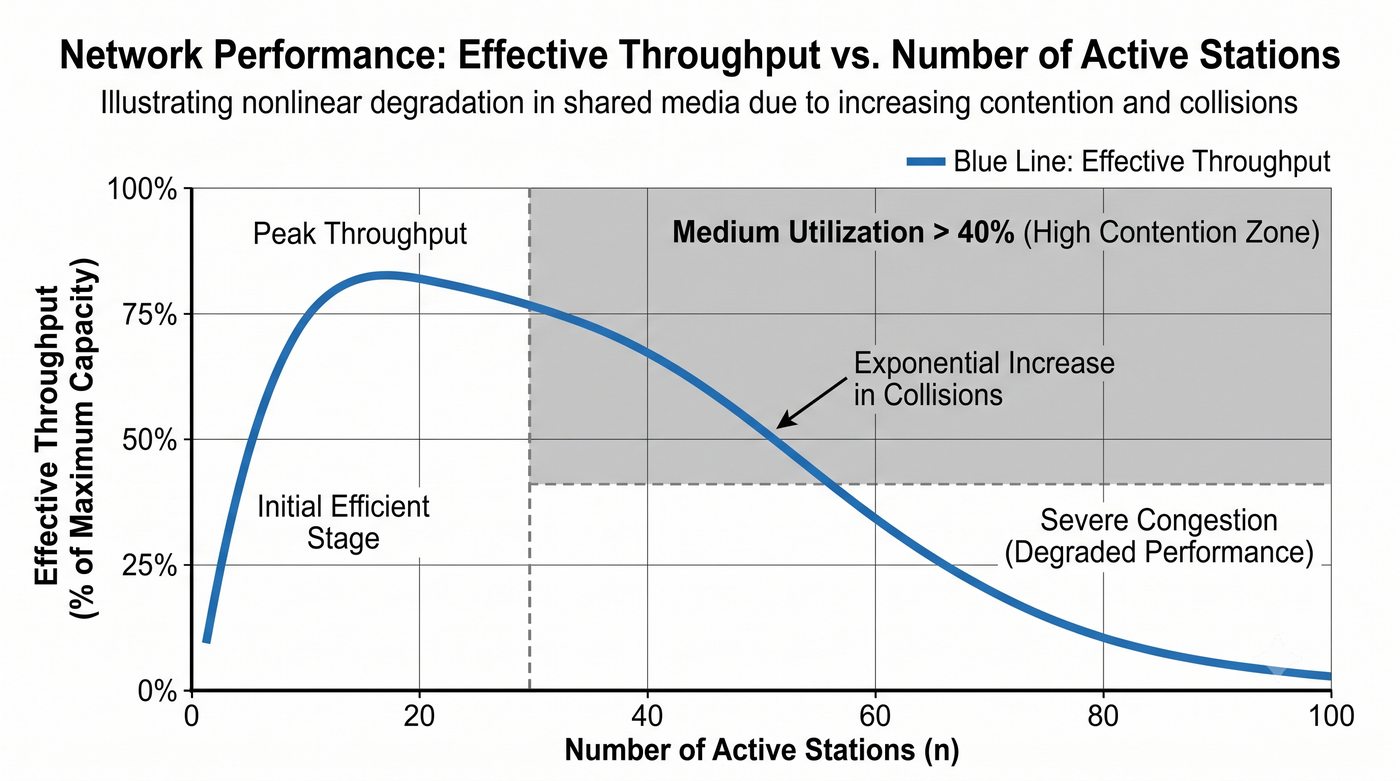
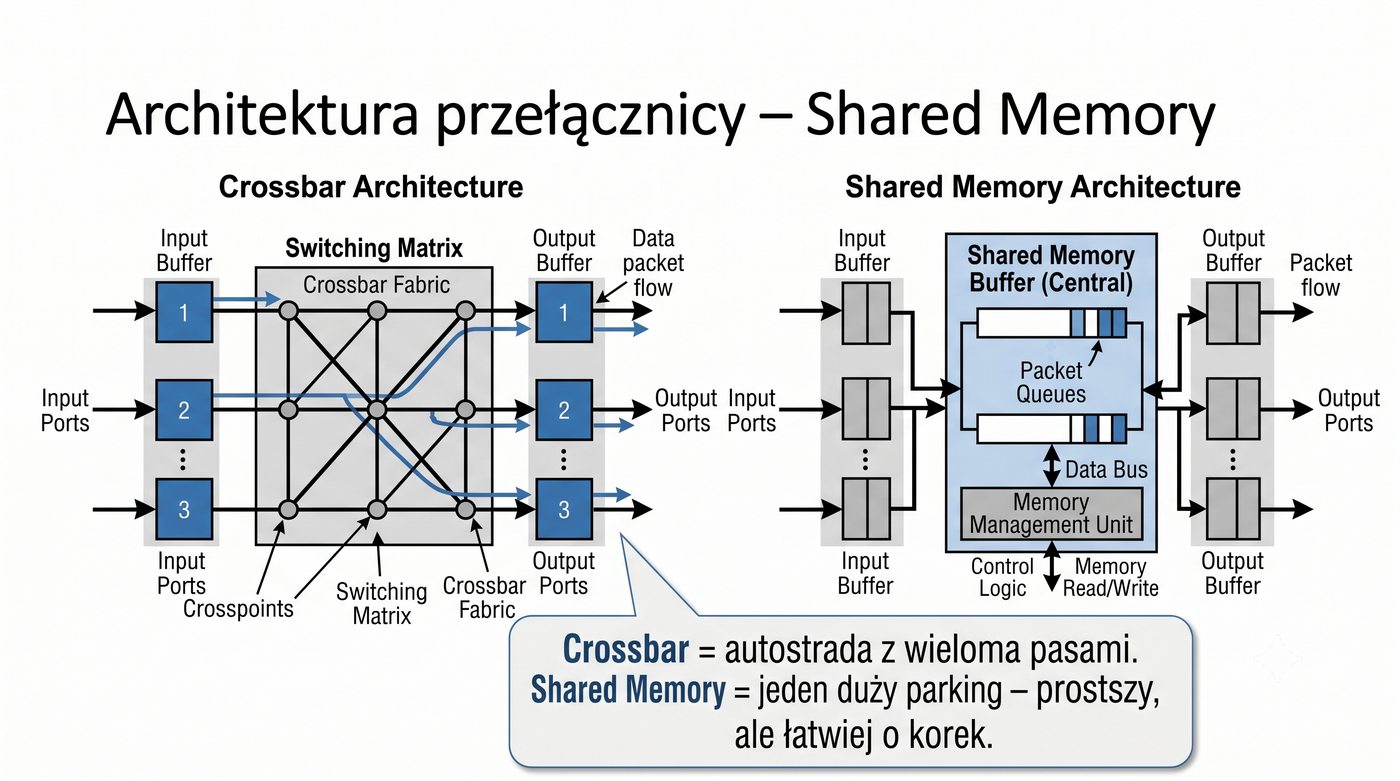
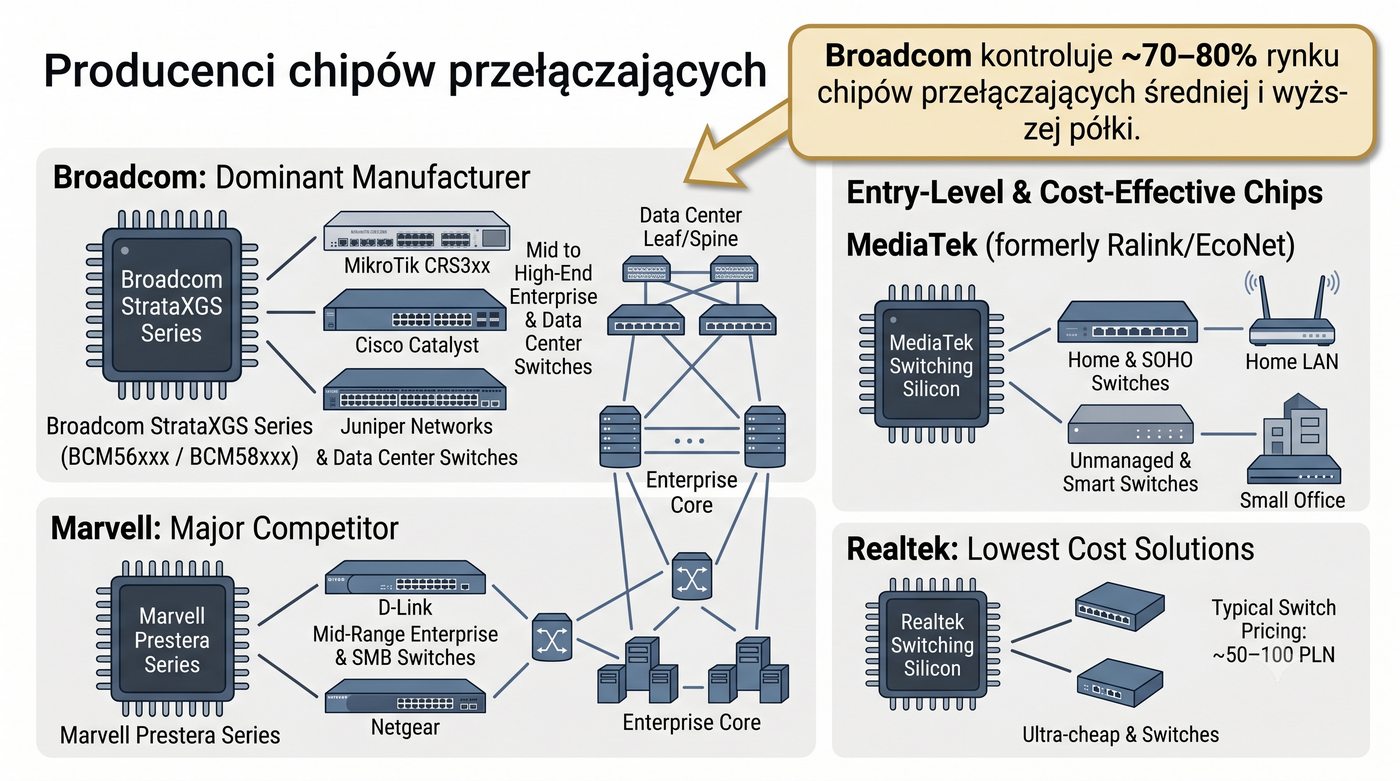
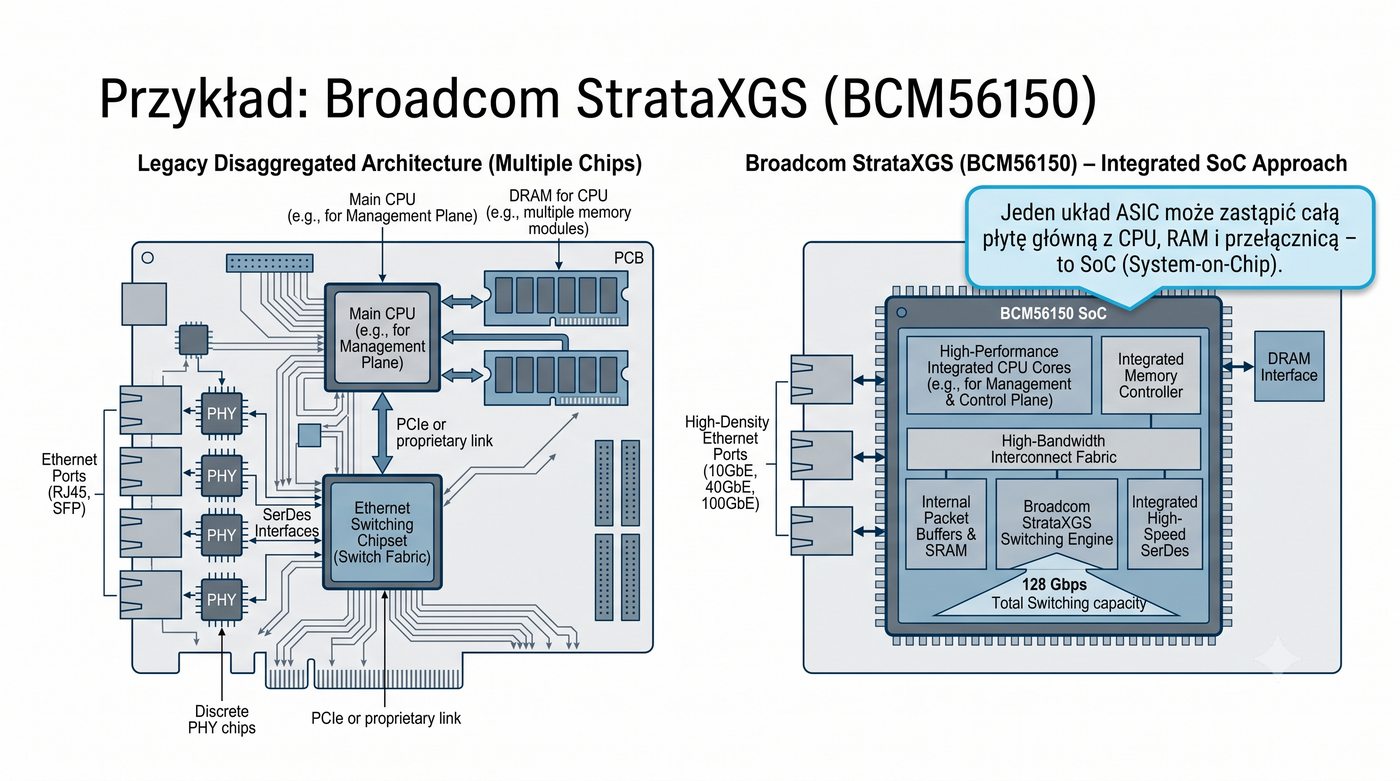
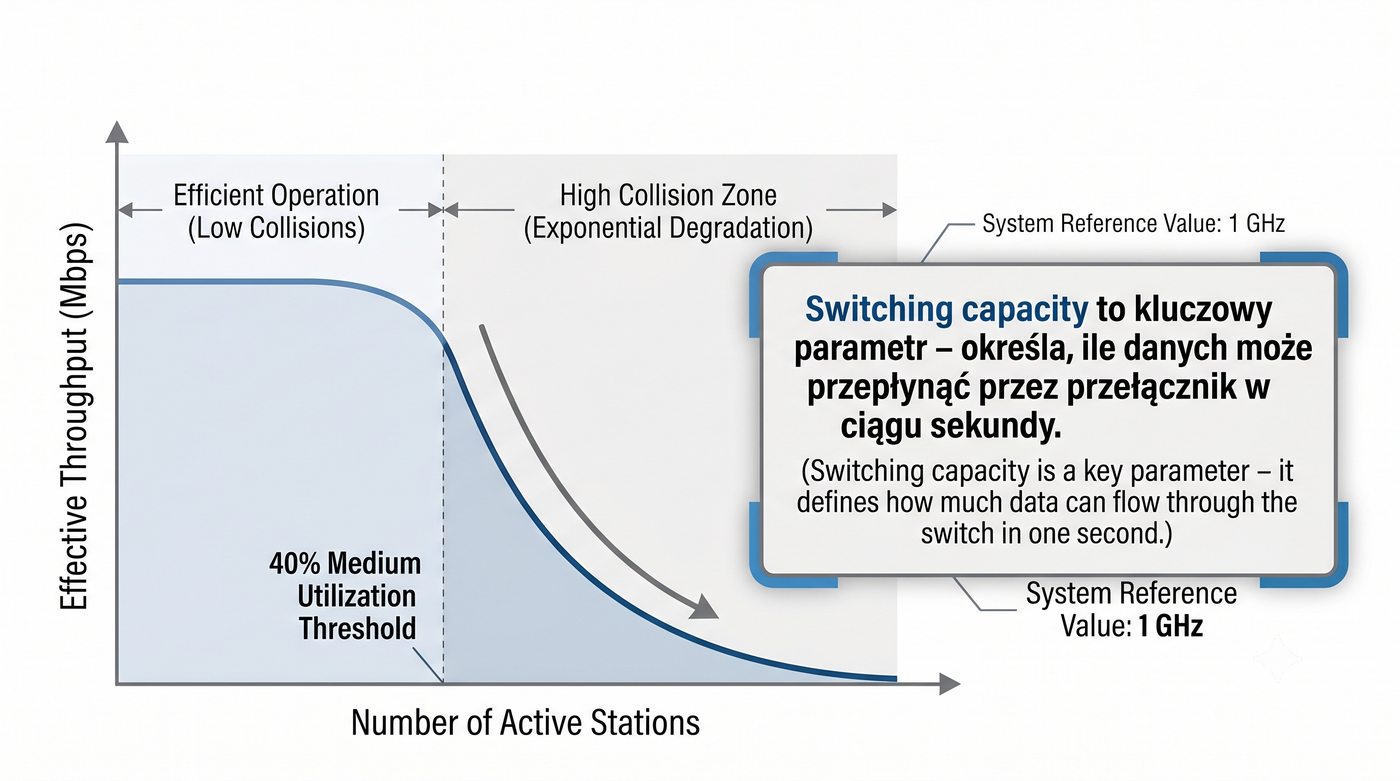
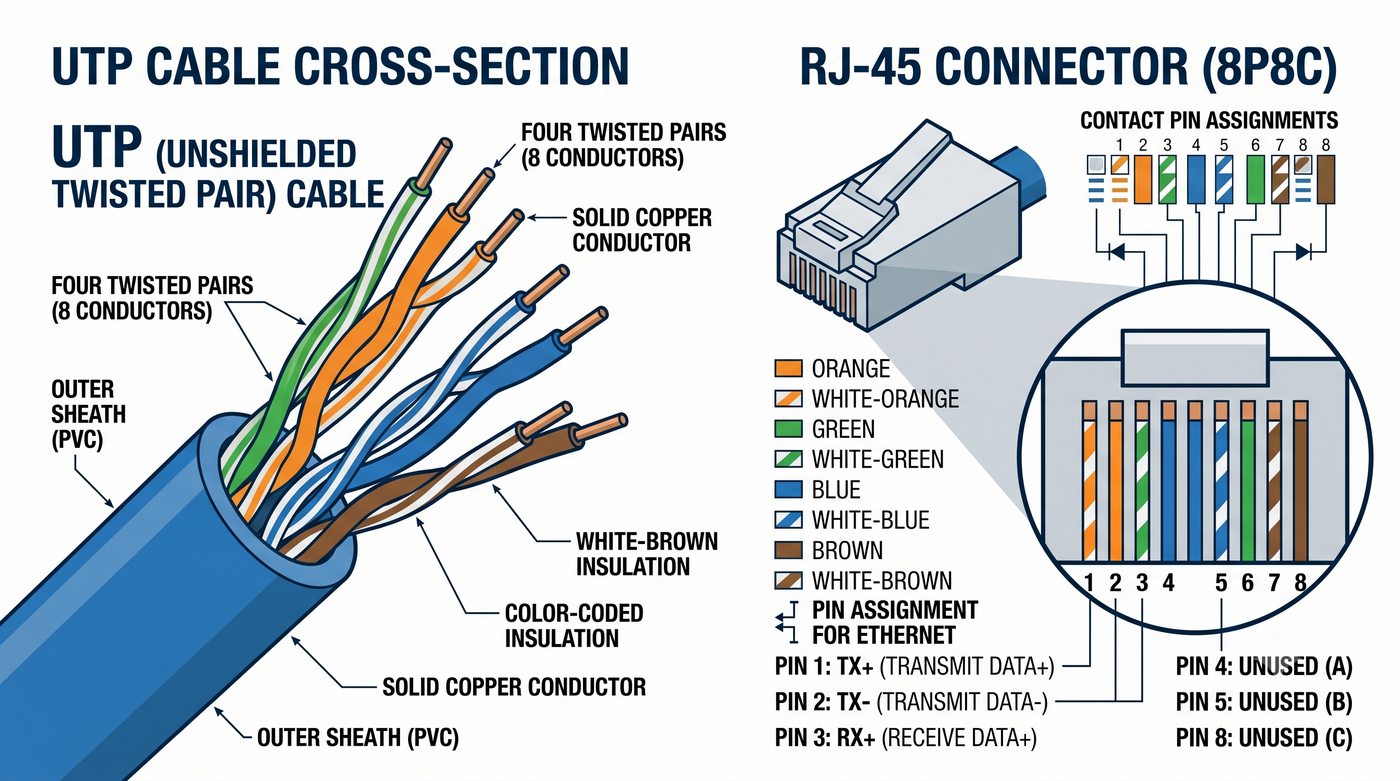
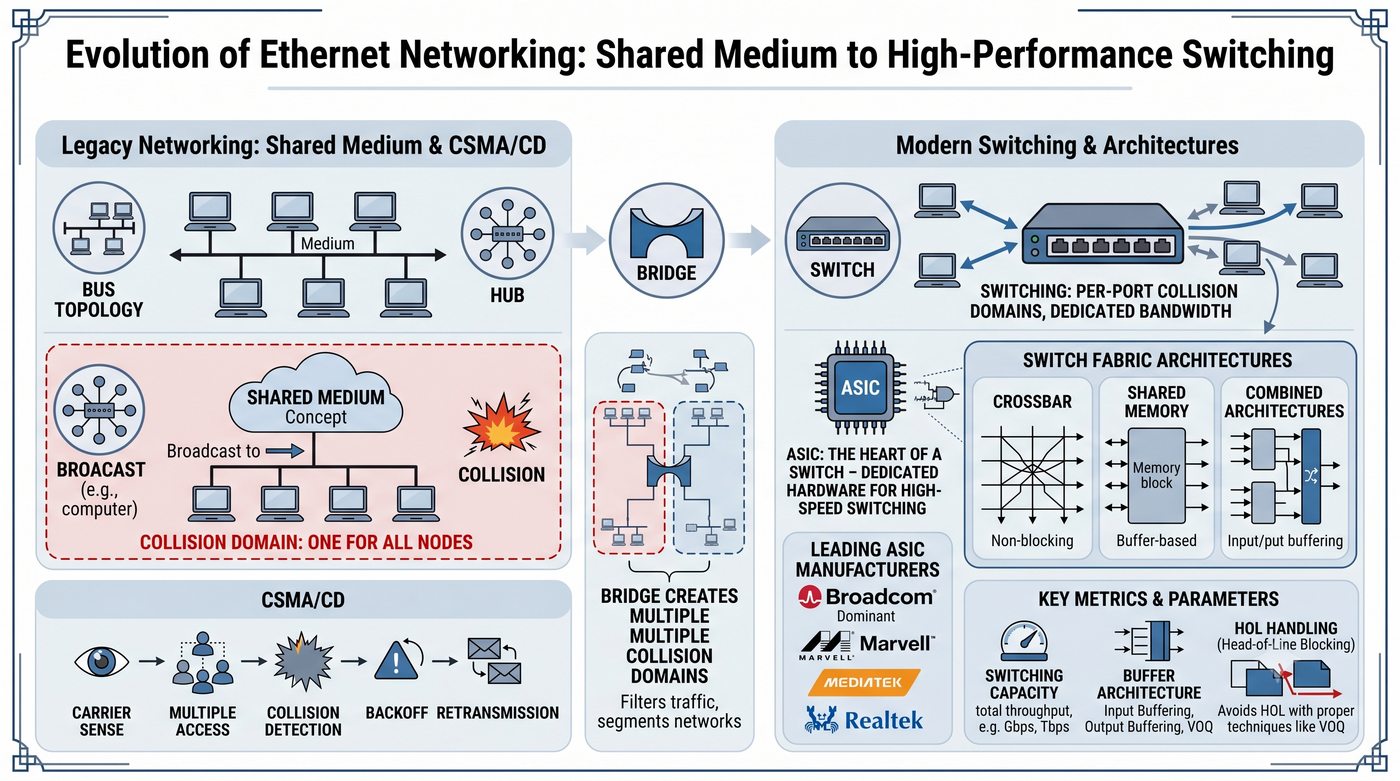
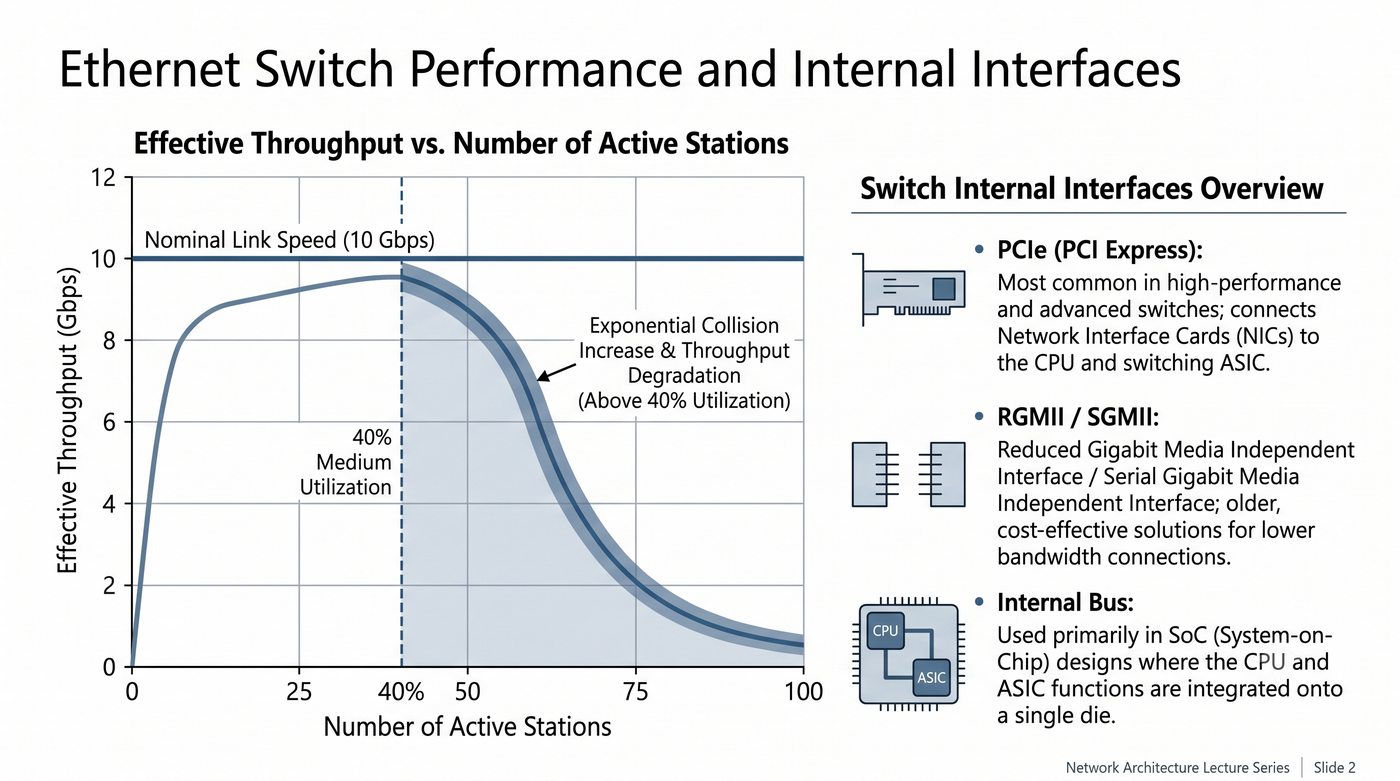
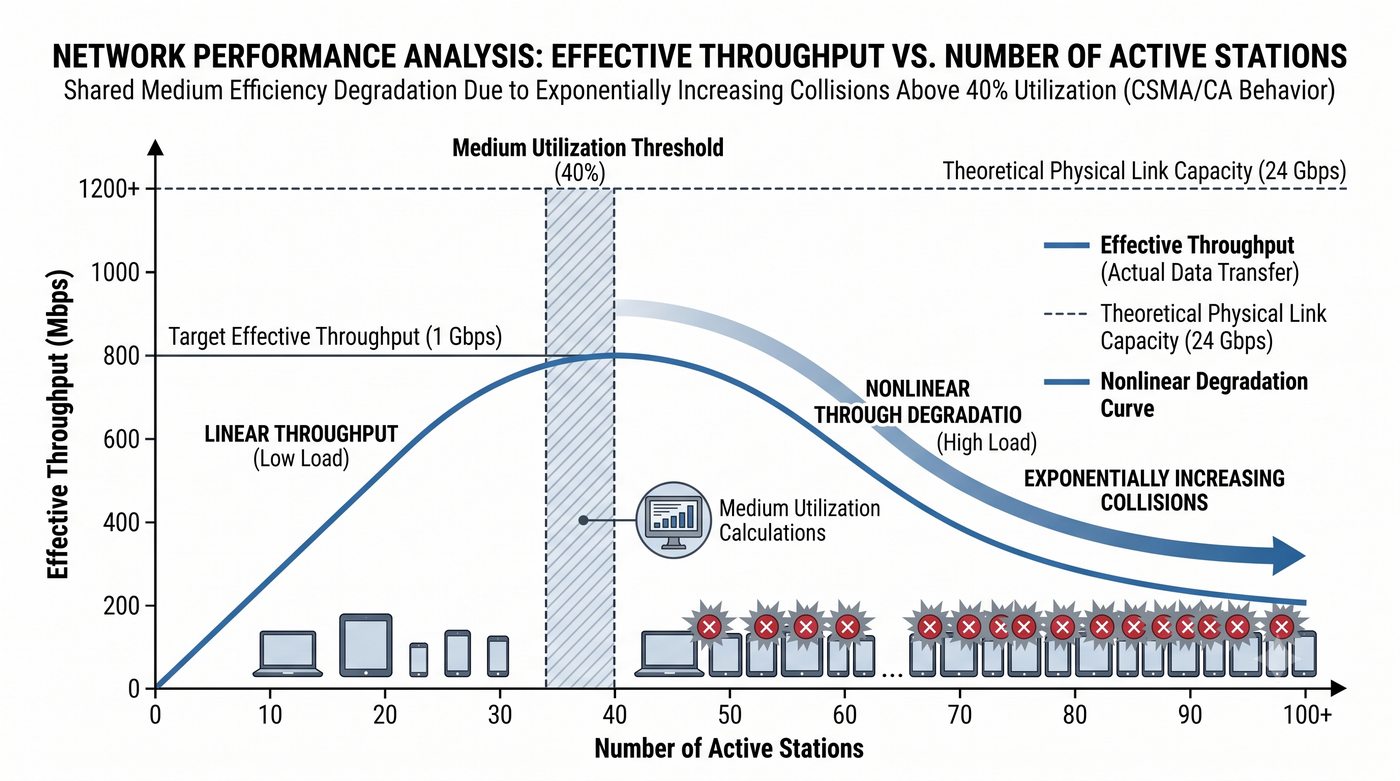
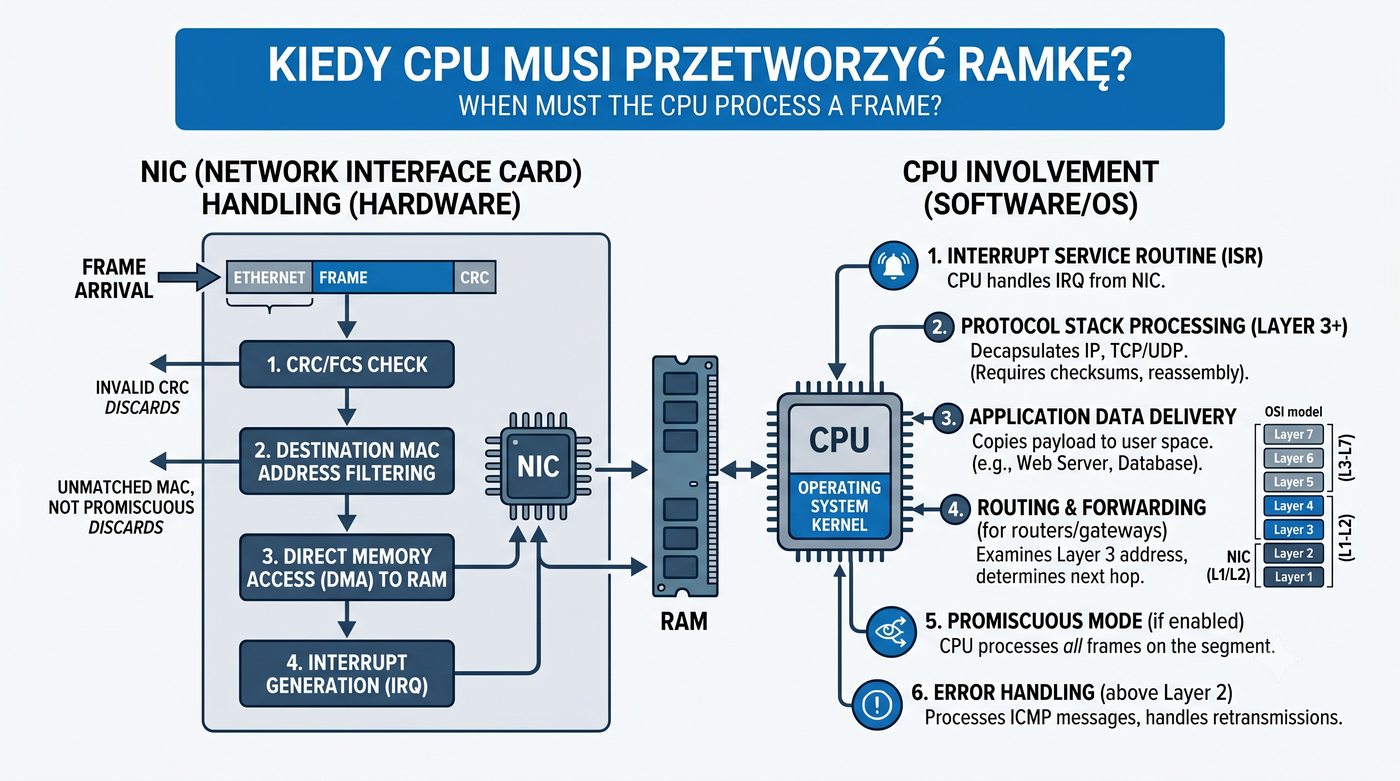
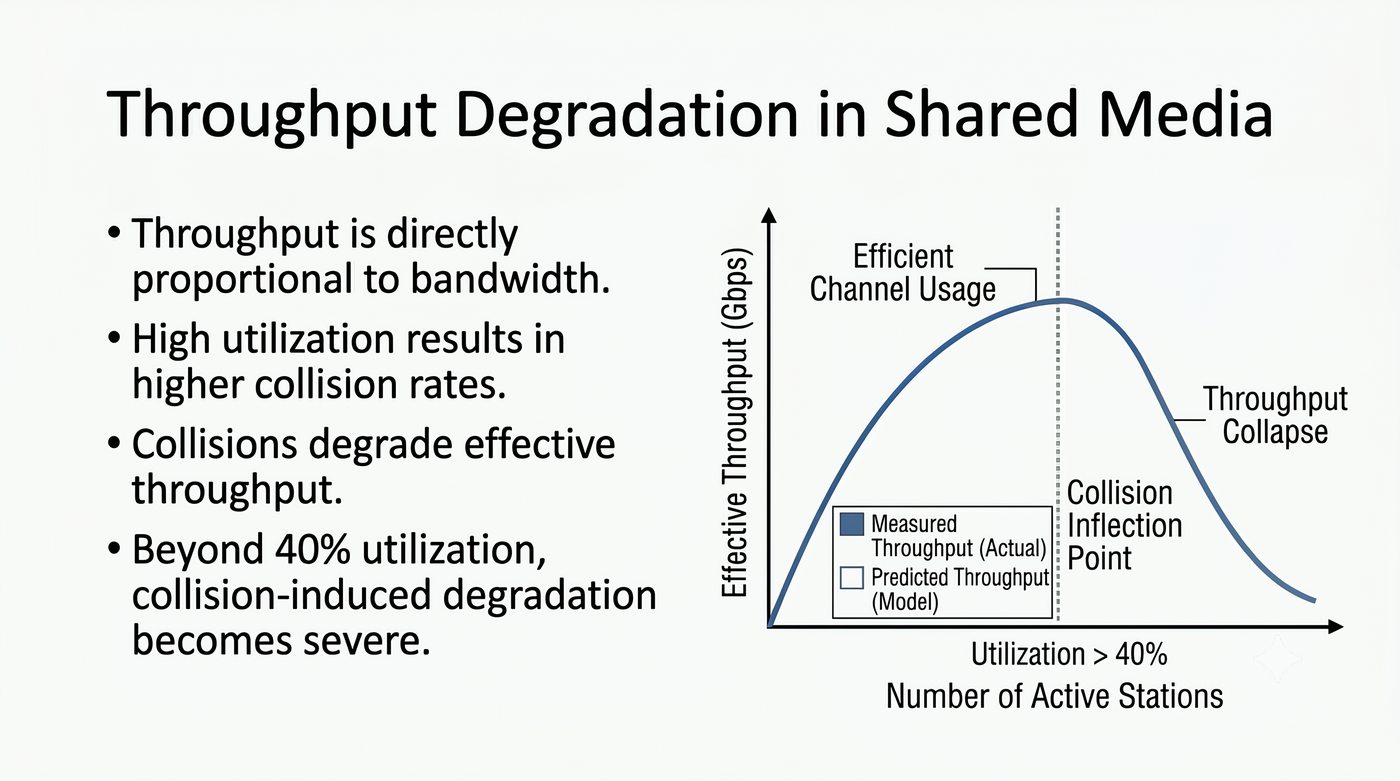
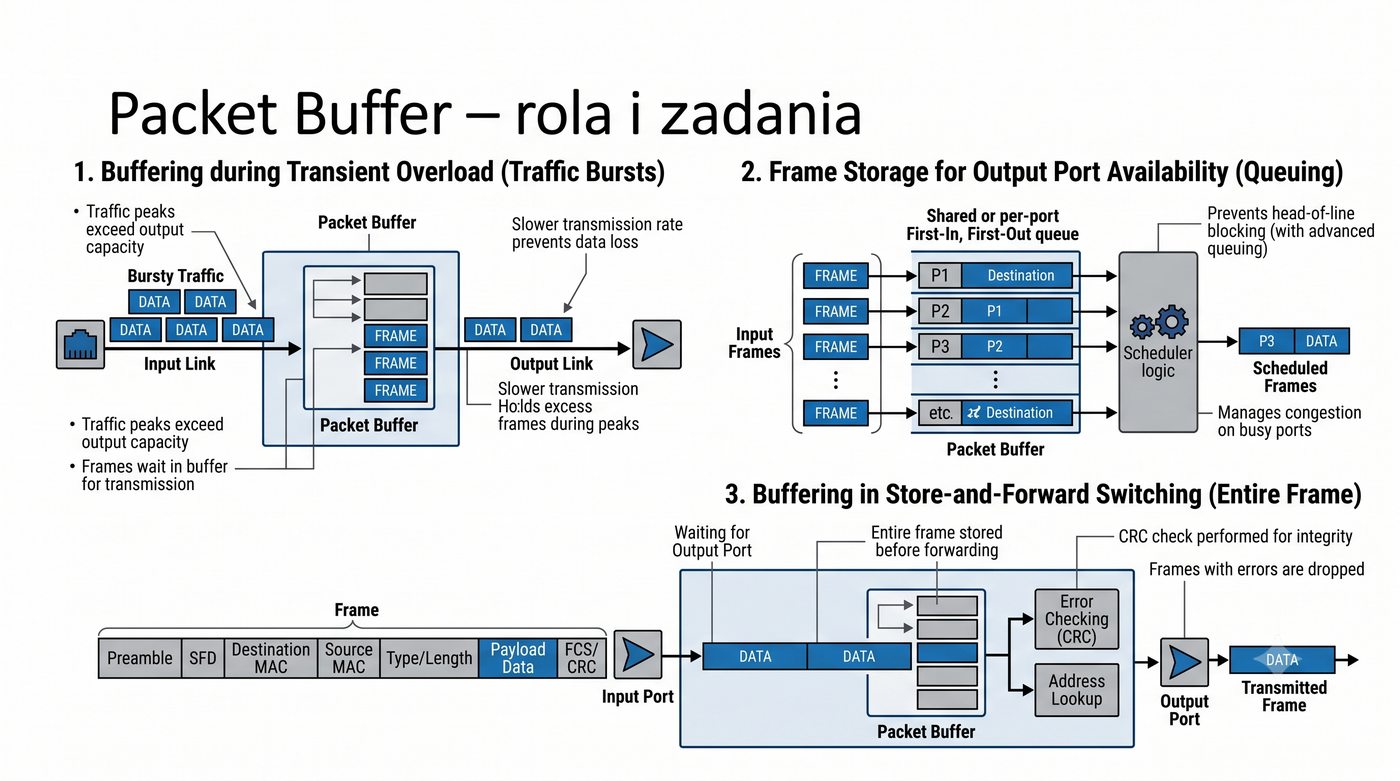
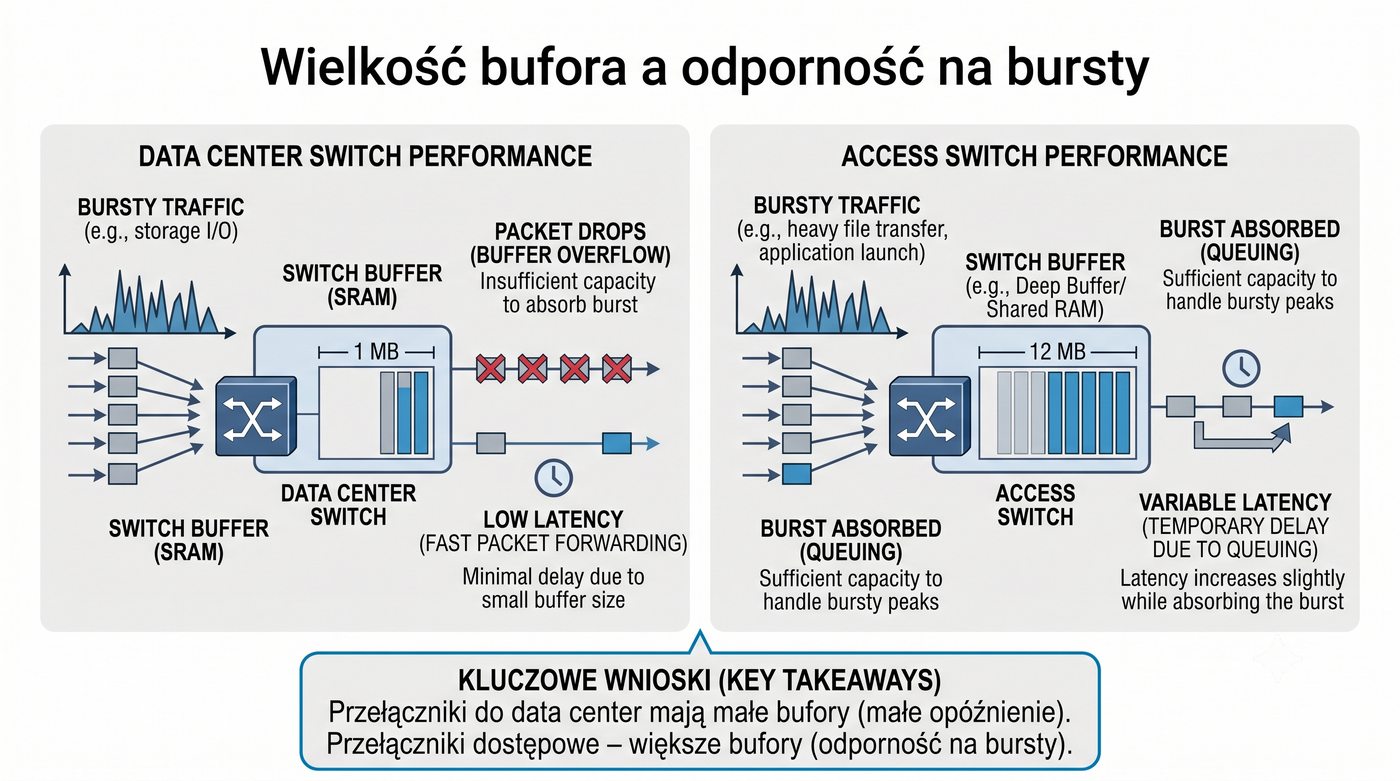
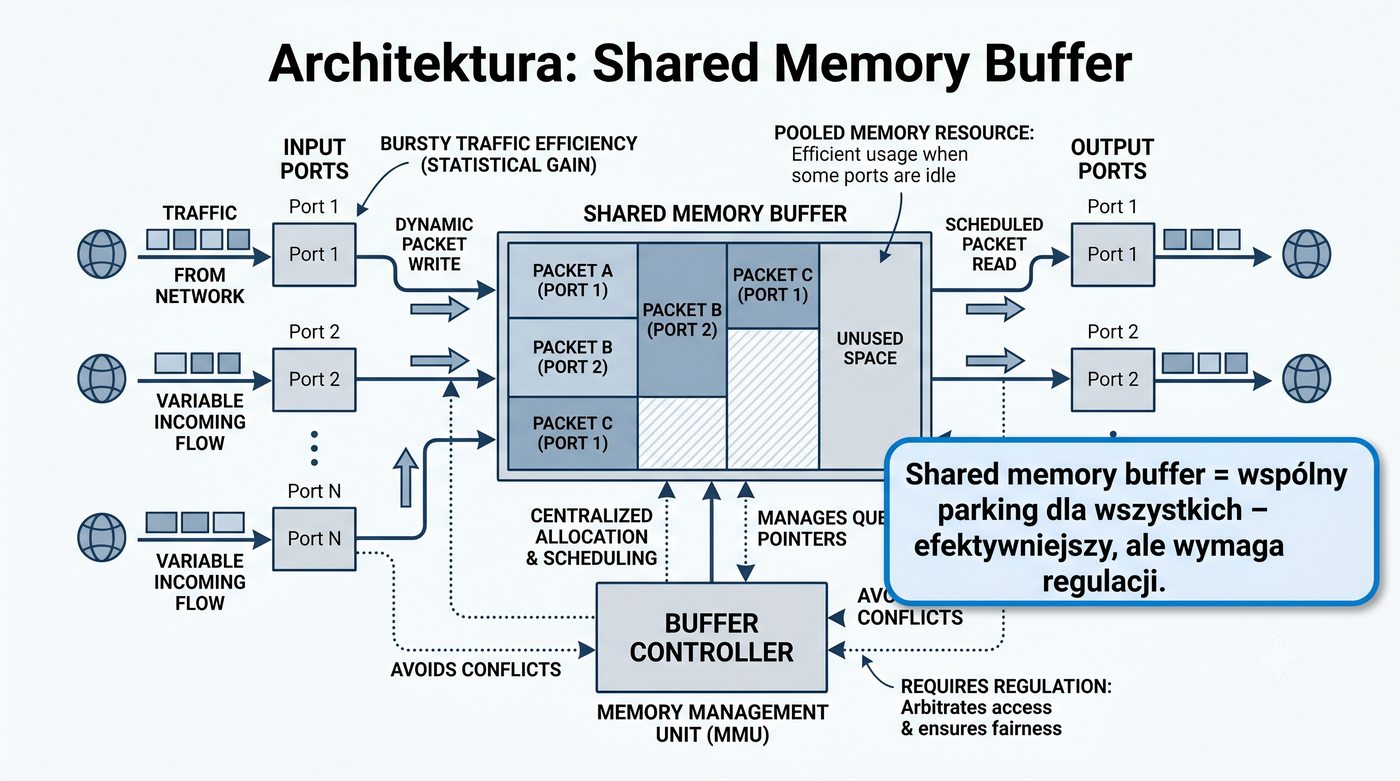
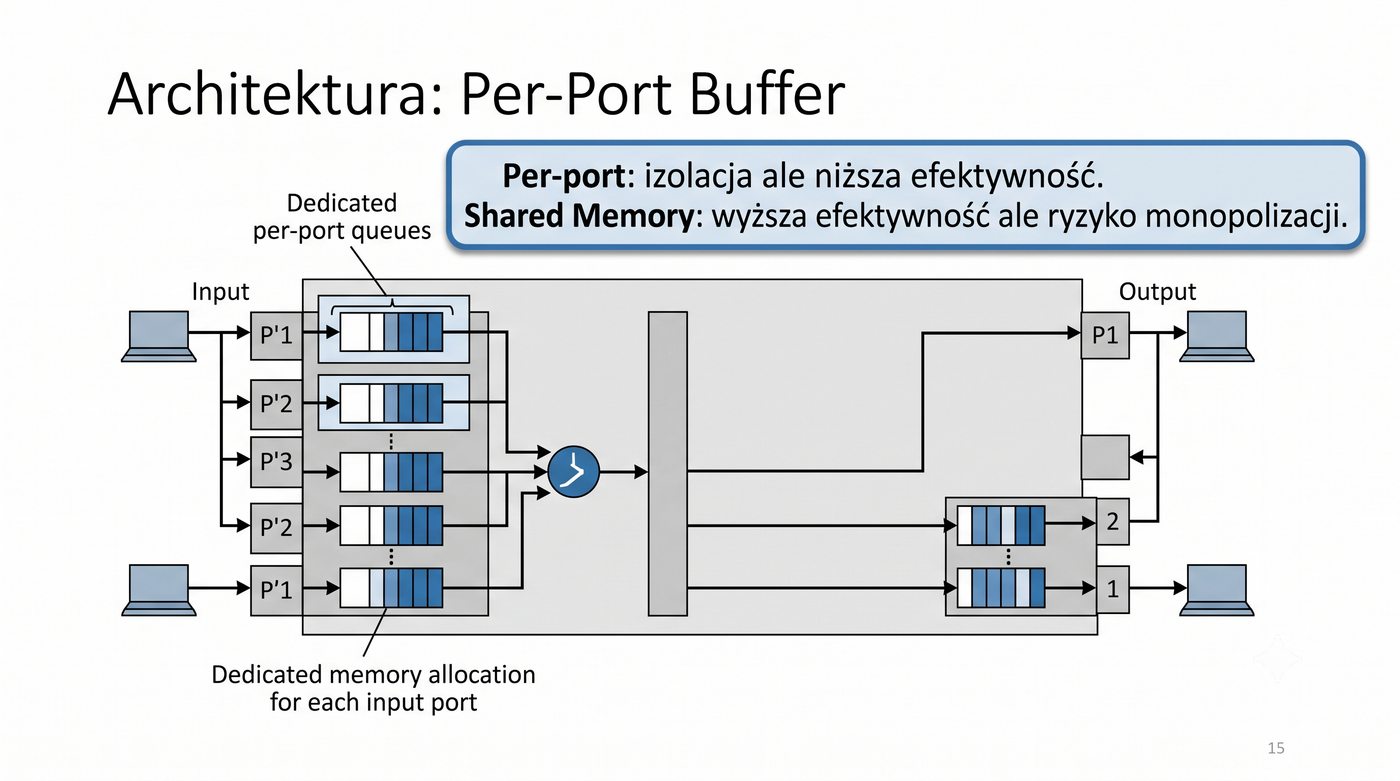
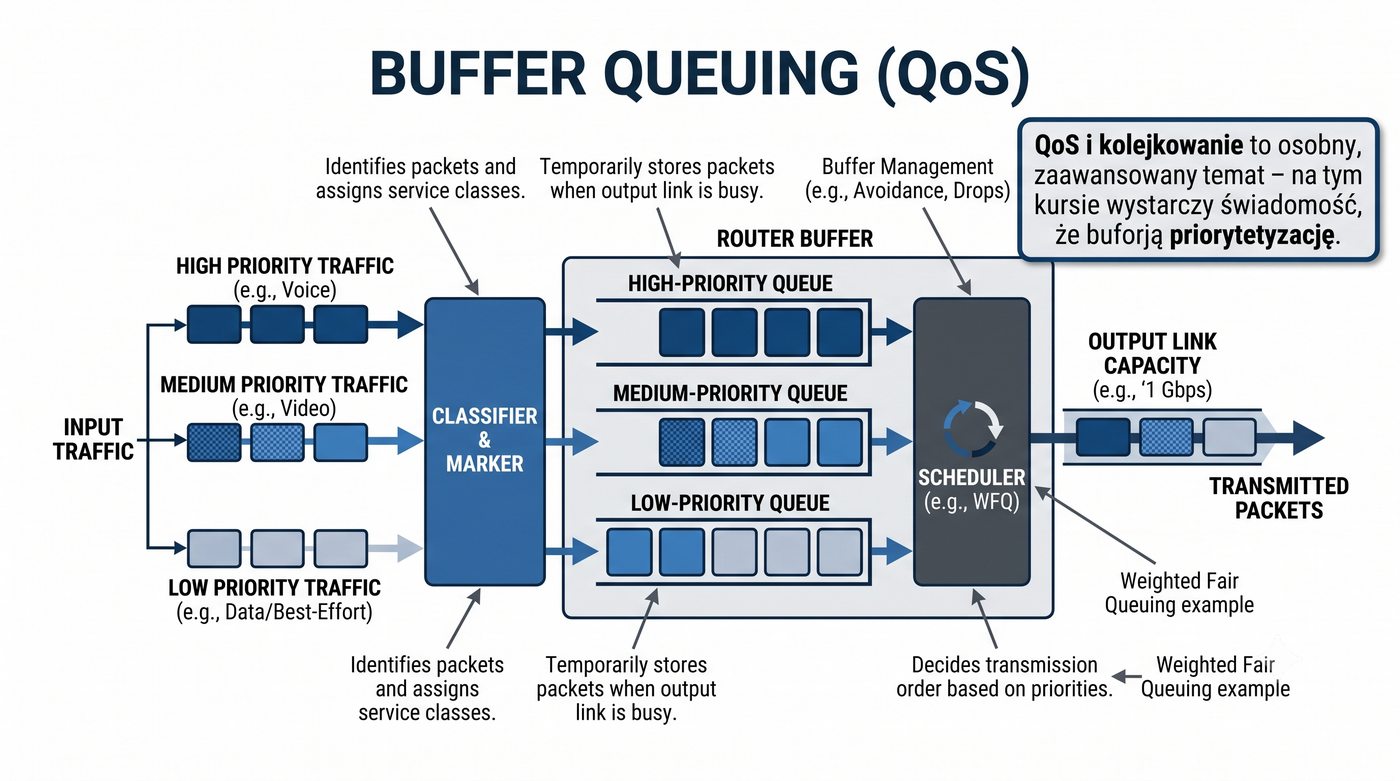
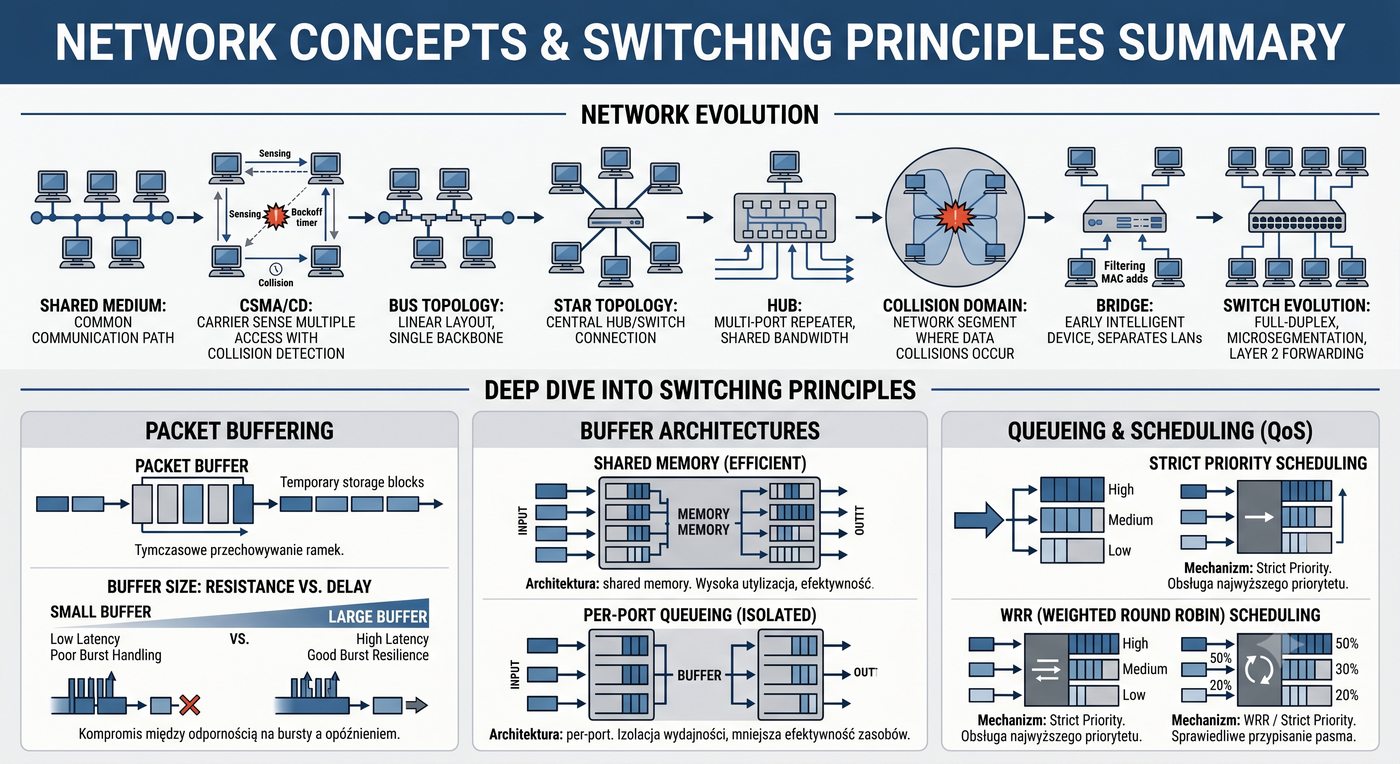
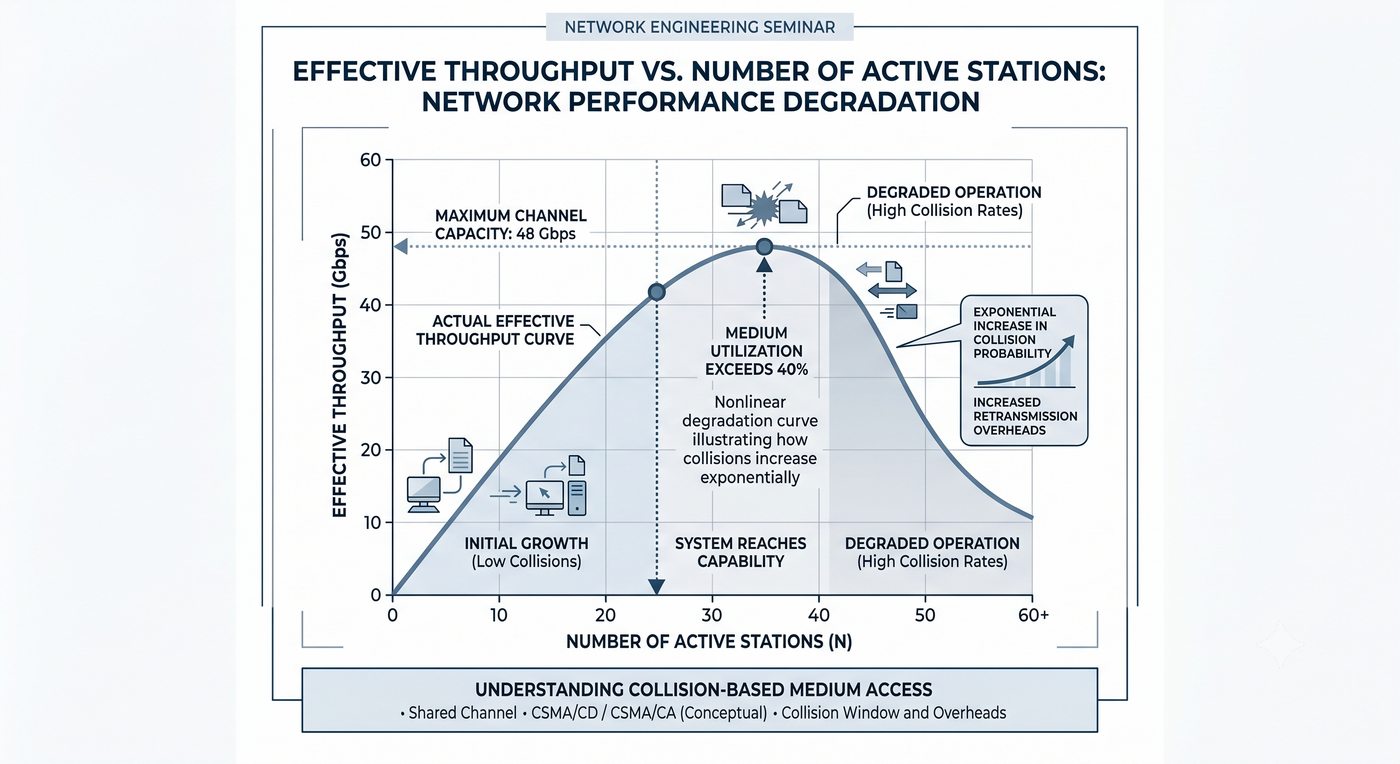
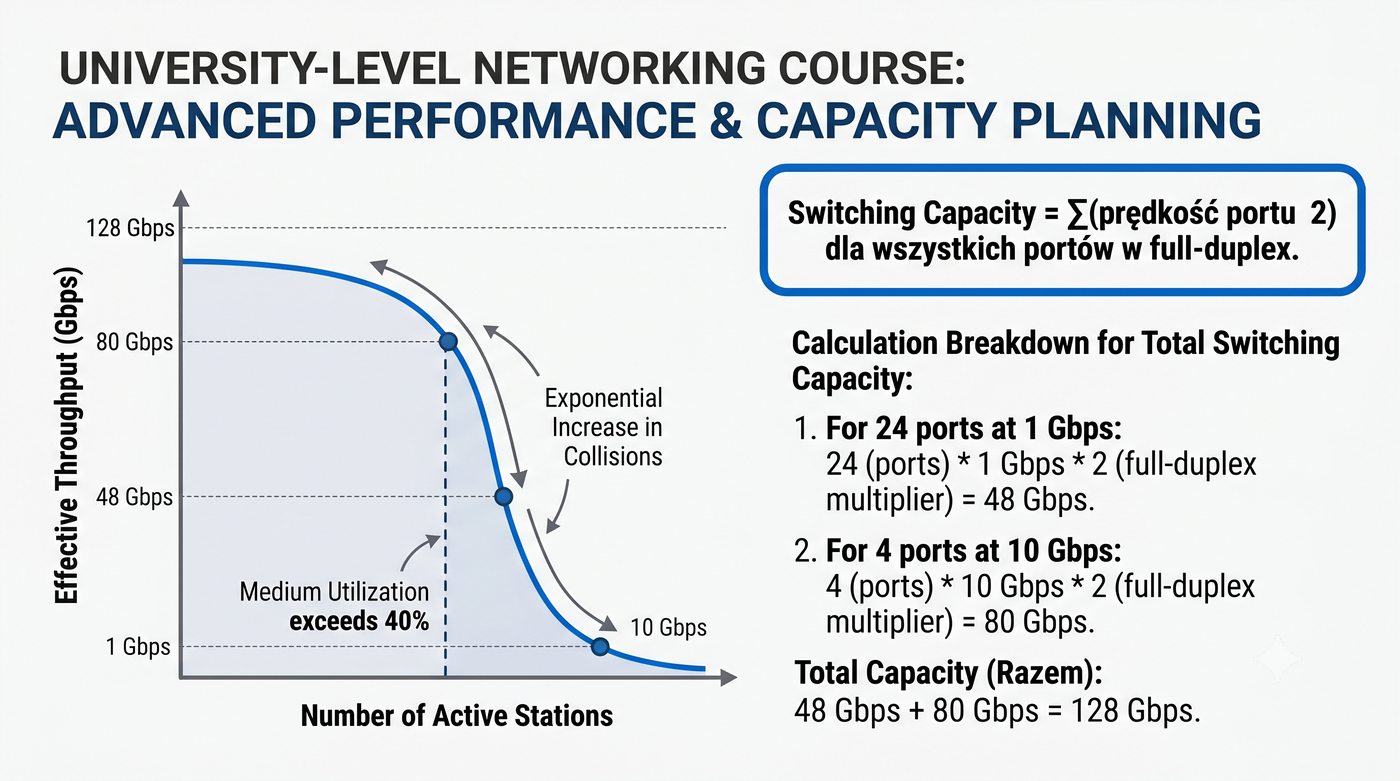
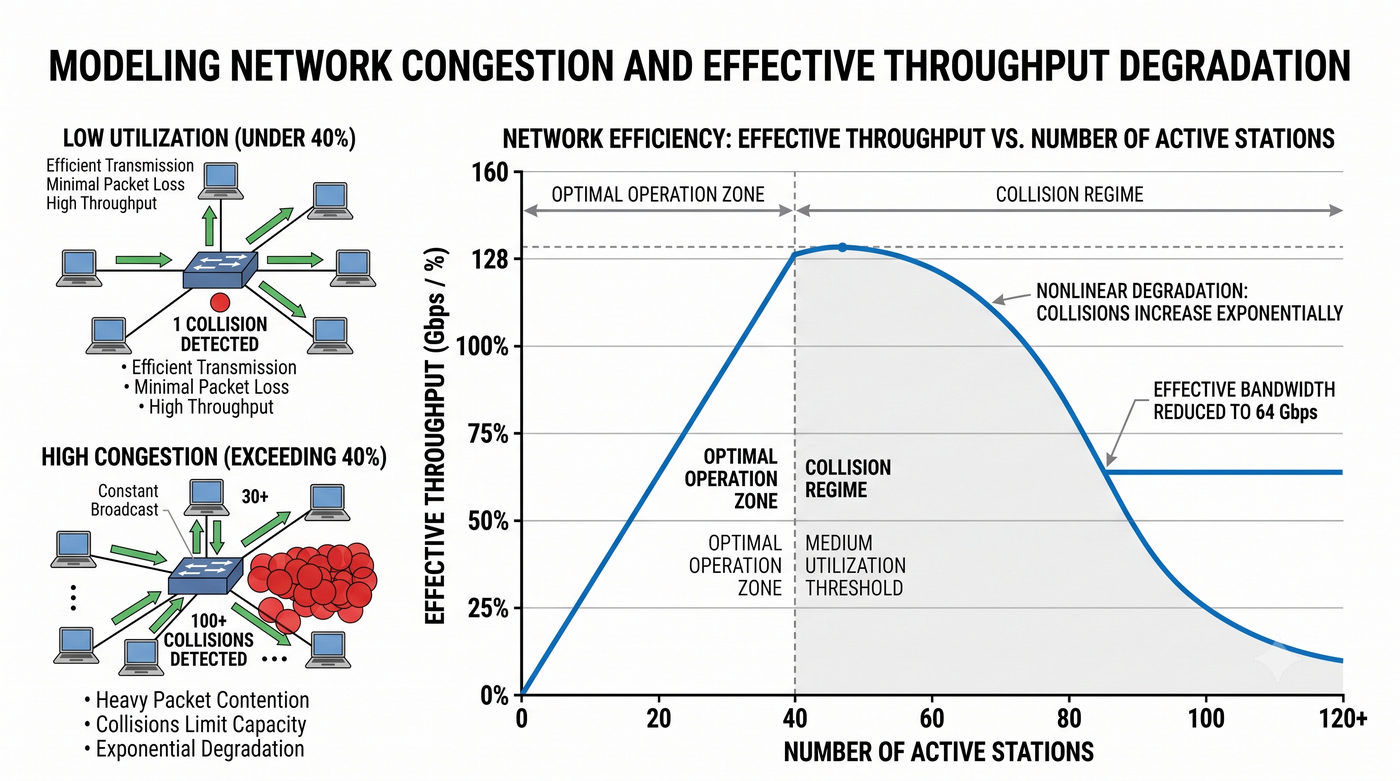
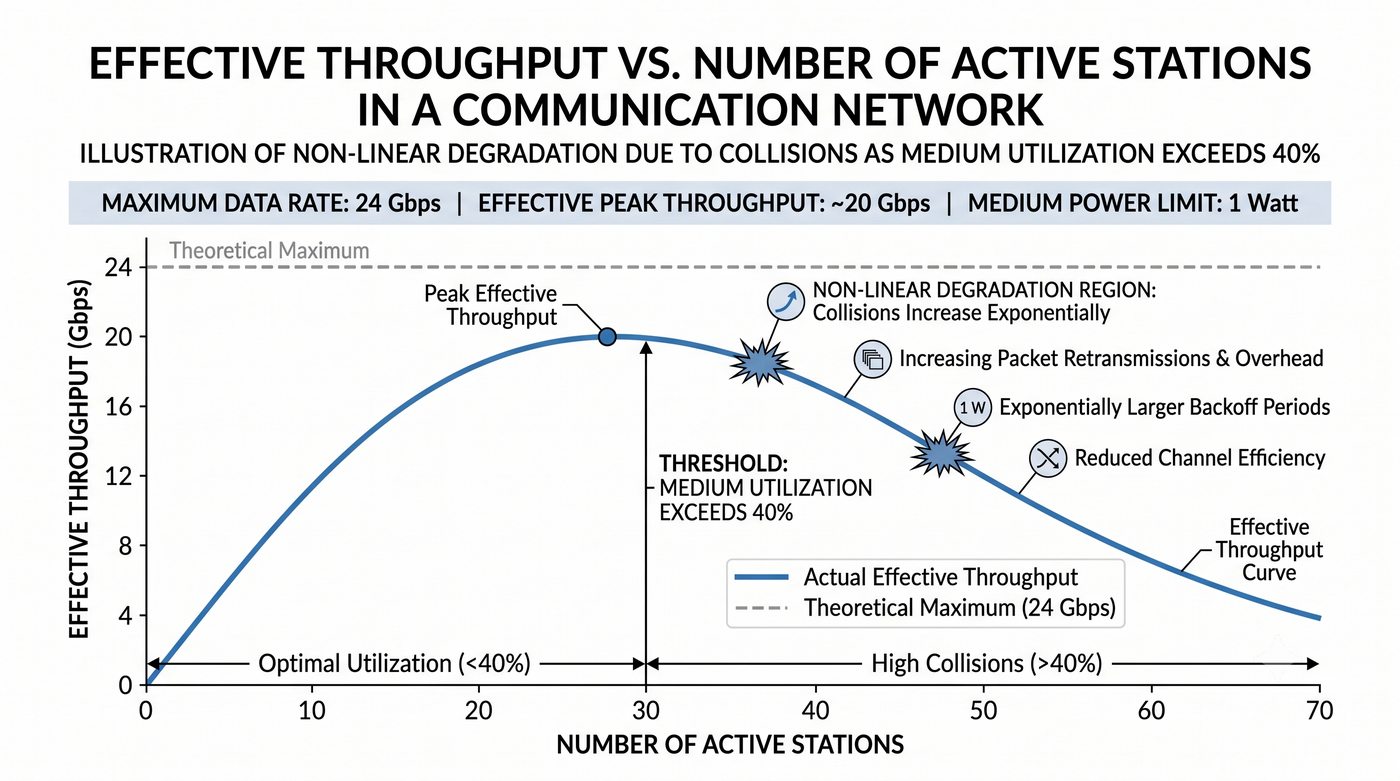
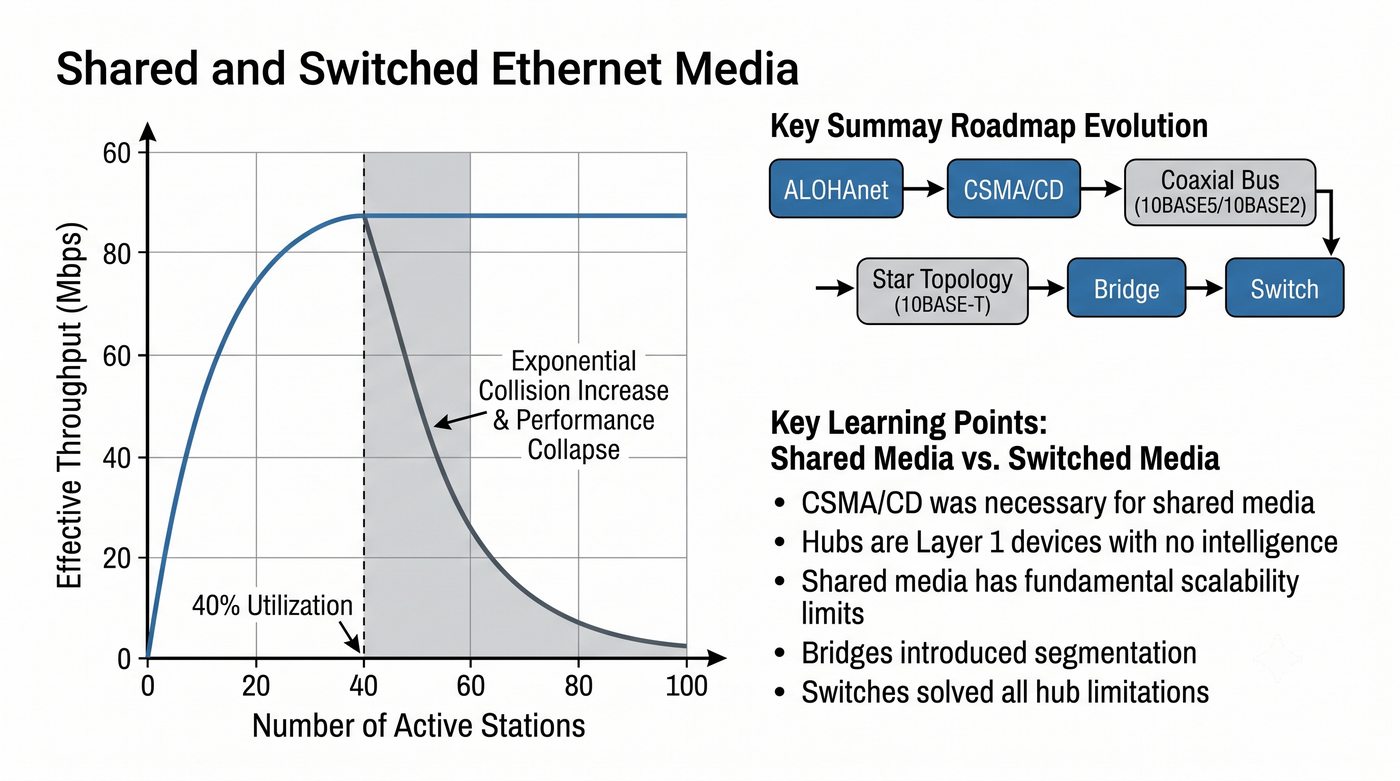
Prezentacja przedstawia wewnętrzną budowę sprzętową przełącznika Ethernet. Omawia wszystkie kluczowe bloki funkcjonalne: ASIC (Switch Fabric) jako serce odpowiedzialne za sprzętowe przełączanie ramek, procesor zarządzający (CPU), pamięć buforową (Packet Buffer) i pamięci CAM/TCAM. Wyjaśnia przepływ ramki przez przełącznik oraz parametry wydajnościowe takie jak switching capacity, non-blocking i over-subscription ratio.